DE statistikk er matematikkfeltet det lister opp fakta og tall der det er et sett med metoder som gjør det mulig for oss å samle inn data og analysere dem, og dermed gjøre det mulig å utføre noen tolkning av dem. Statistikken er delt inn i to deler: beskrivende og inferensiell. Beskrivende statistikk er preget av organisering, analyse og presentasjon av data, mens inferensiell statistikk har som et kjennetegn studiet av et utvalg av en gitt populasjon og, basert på det, utførelsen av analyser og presentasjonen av Terning.
Les også: Hva er en undersøkelses feilmargin?
Prinsipper for statistikk
Deretter vil vi se hovedbegrepene og prinsippene for statistikk. Basert på dem vil det være mulig å definere mer sofistikerte konsepter.
populasjon eller statistisk univers
Befolkningen eller det statistiske universet er sett dannet av alle elementer som deltar i et bestemt forsket emne.
Eksempler på statistisk univers
a) I en by tilhører alle innbyggere det statistiske universet.
b) På en ensidig terning er befolkningen gitt etter antall ansikter.
{1, 2, 3, 4, 5, 6}
Statistisk data
De statistiske dataene er en element som tilhører befolkningen som helhet, åpenbart må disse dataene være involvert i forskningstemaet.
Befolkning |
Statistisk data |
sekssidig terning |
4 |
Brasilianske terrengsykkelmestere |
Henrique Avancini |
Prøve
Vi kaller prøven delmengde dannet basert på statistisk univers. Et utvalg brukes når populasjonen er veldig stor eller uendelig. I tilfeller der det ikke er mulig å samle all informasjon fra det statistiske universet av økonomiske eller logistiske årsaker, er det også nødvendig å bruke prøver.
Valget av et utvalg er ekstremt viktig for en undersøkelse, og det må pålitelig representere befolkningen. Et klassisk eksempel på bruk av prøver i en undersøkelse er å utføre demografisk folketelling av landet vårt.
Variabel
I statistikken er variabelen gjenstand for studier, det vil si temaet som forskningen har til hensikt å studere. For eksempel, når man studerer egenskapene til en by, kan antall innbyggere være variabelt, i tillegg til mengden regn i en gitt periode eller til og med antall busser for transport offentlig. Merk at begrepet variabel i statistikk er avhengig av forskningssammenheng.
Organiseringen av data i statistikken foregår i faser, som i enhver organisasjonsprosess. Opprinnelig velges temaet som skal undersøkes, deretter tenkes metoden for innsamling av forskningsdata, og det tredje trinnet er å gjennomføre samlingen. Etter slutten på dette siste trinnet blir analysen av det som ble samlet utført, og det blir derfor søkt resultater basert på tolkningen. Vi vil nå se noen viktige og nødvendige konsepter for dataorganisasjon.
Ikke stopp nå... Det er mer etter annonseringen;)
rolle
I tilfeller der dataene kan representeres av tall, det vil si når variabelen er kvantitativ, listen for organisering av disse dataene. En liste kan være stigende eller synkende. Hvis en variabel ikke er kvantitativ, det vil si hvis den er kvalitativ, er det ikke mulig å bruke listen, for eksempel hvis dataene er følelser om et bestemt produkt.
Eksempel
I et klasserom ble elevene i meter samlet. De er: 1,70; 1,60; 1,65; 1,78; 1,71; 1,73; 1,72; 1,64.
Siden listen kan organiseres stigende eller synkende, følger det at:
rol: (1,60; 1,64; 1,65; 1,70; 1,71; 1,72; 1,73; 1,78}
Merk at når rullen allerede er samlet, er det mulig å finne en dyse lettere.
Frekvensfordelingstabell
I tilfeller der det er mange elementer i listen og mange repetisjoner av data, blir listen foreldet, ettersom organisasjonen av disse dataene er upraktisk. I disse tilfellene er tabellene og frekvensfordeling de fungerer som et utmerket organisasjonsverktøy.
I fordelingstabellen til absolutt frekvens, vi må angi hvor ofte hver data vises, det vil si antall ganger den vises.
La oss bygge distribusjonstabellen for absolutt frekvens alder, i år, til studentene i en gitt klasse.
Absolutt frekvensfordeling | |
Alder |
Frekvens (F) |
8 |
2 |
9 |
12 |
10 |
12 |
11 |
14 |
12 |
1 |
Totalt (FT) |
41 |
Fra tabellen kan vi få følgende informasjon: i klassen har vi 2 elever i alderen 8, 12 9 år gamle studenter og 12 andre 10 år gamle studenter, og så videre, og nådde totalt 41 studenter. I fordelingstabellen til akkumulerte frekvenser, må vi legge til frekvensen fra forrige rad (i tabellen med absolutt frekvensfordeling).
La oss bygge den kumulative frekvensfordelingstabellen for aldre i samme klasse som i forrige eksempel, se:
Akkumulert frekvensfordeling | |
Alder |
Frekvens (F) |
8 |
2 |
9 |
14 |
10 |
26 |
11 |
40 |
12 |
41 |
Totalt (FT) |
41 |
I tabellen til fordeling av relative frekvenser, prosentandelen der hver data vises brukes. Igjen vil vi gjøre beregningene basert på den absolutte frekvensfordelingstabellen. Vi vet at 41 tilsvarer 100% av elevene i klassen, så for å bestemme prosentdel i hver alder deler vi bare aldersfrekvensen med 41 og multipliserer resultatet med 100, slik at vi kan skrive det i prosent.
2: 41 = 0,048 · 100 → 4,8%
12: 41 = 0,292 · 100 → 29,2%
12: 41 = 0,292 · 100 → 29,2%
14: 41 = 0,341 · 100 → 34,1%
1: 41 = 0,024 · 100 → 2,4%
Relativ frekvensfordeling | |
Alder |
Frekvens (F) |
8 |
4,8% |
9 |
29,2% |
10 |
29,2% |
11 |
34,1% |
12 |
2,4% |
Totalt (FT) |
100% |
Les også:Bruk av ogstatistikk: fFrekvens Deabsolutt og frelativ frekvens
Klasser
I tilfeller der variabelen er kontinuerlig, det vil si når den har flere verdier, er det nødvendig å gruppere dem i reelle intervaller. I statistikken kalles disse intervallene klasser..
Å bygge bordet av frekvensfordeling i klasser, vi må sette intervallene i venstre kolonne, med riktig tittel, og i høyre kolonne må vi legg den absolutte frekvensen til hvert av intervallene, det vil si hvor mange elementer som hører til hver enkelt deres.
Eksempel
Studentenes høyde på 3. året på videregående skole på en skole.
Frekvensfordeling i klasser | |
høyde (meter) |
Absolutt frekvens (F) |
[1,40; 1,50[ |
1 |
[1,50; 1,60[ |
4 |
[1,60; 1,70[ |
8 |
[1,70; 1,80[ |
2 |
[1,80; 1,90[ |
1 |
Totalt (FT) |
16 |
Når vi analyserer frekvensfordelingstabellen i klasser, kan vi se at vi i tredje årsklassen har 1 student som har en høyde mellom 1,40 m og 1,50 m, akkurat som vi har 4 studenter med en høyde mellom 1,50 og 1,60 m, og så suksessivt. Vi kan også observere at elevene har høyde mellom 1,40 m og 1,90 m, forskjellen mellom disse målingene, det vil si mellom den høyeste og den laveste høyden på prøven, kalles amplitude.
Forskjellen mellom øvre og nedre grense for en klasse kalles klassebreddedermed har den andre, som har 4 studenter med høyder mellom 1,50 meter (inkludert) og 1,60 meter (ikke inkludert), en rekkevidde på:
1,60 – 1,50
0,10 meter
Se også: Dispersjonsmål: amplitude og avvik
posisjonsmålinger
Posisjonstiltak brukes i tilfeller der det er mulig å bygge en numerisk rull med dataene eller en frekvenstabell. Disse målingene indikerer elementenes posisjon i forhold til vaktlisten. De tre hovedmålene for posisjon er:
Gjennomsnitt
Vurder listen med elementene (a1, a2, a3, a4,..., TheNei), blir det aritmetiske gjennomsnittet av disse n elementene gitt av:
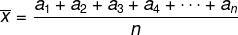
Eksempel
I en dansegruppe ble alderen på medlemmene samlet og representert i følgende liste:
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
La oss bestemme gjennomsnittsalderen til medlemmene i denne dansegruppen.
I henhold til formelen må vi legge til alle elementene og dele dette resultatet med antall elementer i listen, slik:
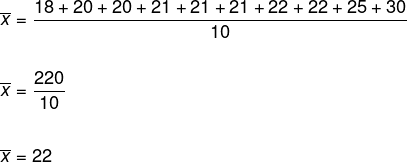
Derfor er gjennomsnittsalderen på medlemmene 22 år.
For å lære mer om dette posisjonsmål, les teksten vår: Mémorgen.
median
Medianen er gitt av det sentrale elementet i en liste som har et merkelig antall elementer. Hvis listen har et jevnt antall elementer, må vi vurdere de to sentrale elementene og beregne det aritmetiske gjennomsnittet mellom dem.
Eksempel
Tenk på listen nedenfor.
(2, 2, 3, 3,4, 5, 6, 7, 9)
Merk at element 4 deler rollen i to like deler, så det er det sentrale elementet.
Eksempel
Beregn medianalderen til dansegruppen.
Husk at listen over aldre for denne dansegruppen er gitt av:
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Merk at antall elementer i denne listen er lik 10, så det er ikke mulig å dele listen i to like deler. Så vi må ta to sentrale elementer og utføre det aritmetiske gjennomsnittet av disse verdiene.
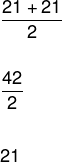
Se flere detaljer om dette posisjonstiltaket i teksten vår: Median.
Mote
Vi vil kalle mote det elementet i rollen som har høyest frekvens, det vil si elementet som vises mest i den.
Eksempel
La oss bestemme moten til dansegruppens aldersrull.
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Elementet som vises mest er 21, så modusen er lik 21.
Spredningstiltak
Spredningstiltak er brukes i tilfeller der gjennomsnittet ikke lenger er tilstrekkelig. Tenk deg for eksempel at to biler i gjennomsnitt har tilbakelagt 40 000 kilometer. Bare med kunnskap om gjennomsnitt kan vi si at de to bilene gikk bestemte kilometer hver, ikke sant?
Tenk deg imidlertid at en av bilene har tilbakelagt 79.000 kilometer, og den andre 1000 kilometer, merk at bare med gjennomsnittlig informasjon er det ikke mulig å komme med uttalelser med presisjon.
På spredningstiltak vil fortelle oss hvor langt elementene i en numerisk liste er fra det aritmetiske gjennomsnittet. Vi har to viktige mål for spredning:
Variasjon (σ2)
La oss kalle det aritmetiske gjennomsnittet av kvadratene av forskjellen mellom hvert element i rullen og det aritmetiske gjennomsnittet av den rullen som varians. Avviket er representert med: σ2.
Tenk på listen (x1, x2, x3,…, XNei) og at det har aritmetisk gjennomsnittx. Avviket er gitt av:
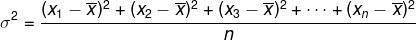
Standardavvik (σ)
Standardavviket er gitt av roten til variansen, det forteller oss hvor mye et element er spredt i forhold til gjennomsnittet. Standardavviket er betegnet med σ.
Eksempel
Bestem standardavviket til datasettet (4, 7, 10). Merk at for dette er det nødvendig å bestemme avviket først, og at det for det er nødvendig å først beregne gjennomsnittet av disse dataene.
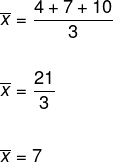
Ved å erstatte disse dataene i variansformelen har vi:
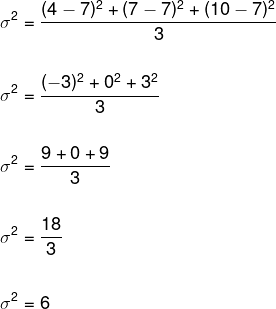
For å bestemme standardavviket, må vi trekke ut roten til variansen.
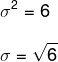
Les mer: Dispersjonsmål: avvik og standardavvik
Hva er statistikk for?
Vi så at statistikken er relatert til Telle- eller dataorganisasjonsproblemer. I tillegg har den en viktig rolle i utviklingen av verktøy som muliggjør prosessen med å organisere data, for eksempel tabeller. Statistikk er også til stede i ulike fagfelt, basert på datainnsamling og behandling, er det mulig å jobbe med matematiske modeller som tillater videre utvikling i det studerte området. Noen felt der statistikk er grunnleggende: økonomi, meteorologi, markedsføring, idrett, sosiologi og geofag.
I meteorologi, for eksempel, blir data samlet inn i en viss periode, etter at de er organisert, blir de behandlet, og så, med basert på dem, er det bygget en matematisk modell som lar oss si om klimaet fra tidligere dager med større grad av pålitelighet. Statistikk er en vitenskapsgren som lar oss komme med uttalelser med en viss grad av pålitelighet, men aldri 100% sikkerhet.
Statistiske inndelinger
Statistikk er delt inn i to deler, beskrivende og inferensiell. Den første er relatert til å telle elementene som er involvert i forskningen, disse elementene telles en etter en. På Beskrivende statistikk, våre viktigste verktøy er posisjonstiltak, som gjennomsnitt, median og modus, samt spredningstiltak som avvik og standardavvik, har vi også frekvenstabeller og grafikk.
Fortsatt i beskrivende statistikk har vi en veldig veldefinert metodikk for en presentasjon av data med en betydelig grad av pålitelighet som går gjennom organisering og innsamling, sammendrag, tolkning og representasjon og til slutt dataanalyse. Et klassisk eksempel på bruk av beskrivende statistikk forekommer i folketellingen (hvert 10. år) av det brasilianske instituttet for geografi og statistikk (IBGE).
DE inferensiell statistikk, i sin tur er det ikke preget av å samle inn data fra elementene i en befolkning en etter en, men ved å utføre analyse av et utvalg av denne populasjonen, og trekker konklusjoner om henne. I inferensiell statistikk må det utvises forsiktighet når du velger utvalget, da det må representere befolkningen veldig bra. Noen innledende resultater, som gjennomsnitt, i inferensiell statistikk kalt håp, blir utledet basert på kunnskap om beskrivende statistikk.
Inferensiell statistikk brukes for eksempel i valgmålingene. Et utvalg av befolkningen velges, på en måte som representerer den, og dermed blir forskningen utført. Når vi velger et utvalg som ikke representerer denne populasjonen veldig bra, sier vi at forskningen er det forutinntatt og derfor upålitelig.
Øvelser løst
Spørsmål 1 - (U. F. Juiz de Fora - MG) En fysikklærer brukte en test, verdt 100 poeng, på sine 22 studenter og oppnådde som et resultat fordeling av karakterer, sett i følgende tabell:
40 |
20 |
10 |
20 |
70 |
60 |
90 |
80 |
30 |
50 |
50 |
70 |
50 |
20 |
50 |
50 |
10 |
40 |
30 |
20 |
60 |
60 |
– |
– |
Utfør følgende databehandlinger:
a) Skriv listen over disse notatene.
b) Bestem den relative frekvensen til den høyeste tonen.
Vedtak
a) For å lage listen over disse notatene, må vi skrive dem stigende eller synkende. Så vi må:
10, 10, 20, 20, 20, 20, 30, 30, 40, 40, 50, 50, 50, 50, 50, 60, 60, 60, 80, 90
b) Ser vi på rullen, kan vi se at den høyeste tonen var lik 90 og at dens absolutte frekvens er lik 1, da den bare vises en gang. For å bestemme den relative frekvensen, må vi dele den absolutte frekvensen til den noten med den totale frekvensen, i dette tilfellet lik 22. Og dermed:
relativ frekvens
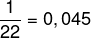
For å passere dette tallet i prosent, må vi multiplisere det med 100.
0,045 · 100
4,5%
Spørsmål 2 - (Enem) Etter å ha rullet en terningformet dyse med ansikter nummerert fra 1 til 6, 10 ganger på rad, og legg merke til antallet oppnådd i hvert trekk, følgende distribusjonstabell for frekvenser.
Antatt antall |
Frekvens |
1 |
4 |
2 |
1 |
4 |
2 |
5 |
2 |
6 |
1 |
Gjennomsnittet, medianen og modusen for denne frekvensfordelingen er henholdsvis:
a) 3, 2 og 1
b) 3, 3 og 1
c) 3, 4 og 2
d) 5, 4 og 2
e) 6, 2 og 4
Vedtak
Alternativ B.
For å bestemme gjennomsnittet, merk at det er gjentakelse av tallene som er oppnådd, så vi vil bruke det vektede aritmetiske gjennomsnittet.
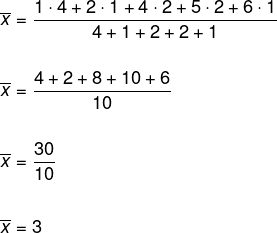
For å fastslå medianen, må vi ordne listen på stigende eller synkende måte. Husk at frekvensen er antall ganger ansiktet dukker opp.
1, 1, 1, 1, 2, 4, 4, 5, 5, 6
Siden antall elementer i vaktlisten er jevn, må vi beregne det aritmetiske gjennomsnittet av de sentrale elementene som deler vaktlisten i to for å bestemme medianen, slik:
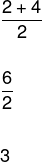
Modusen er gitt av det elementet som vises mest, det vil si at den har den høyeste frekvensen, så vi har at modusen er lik 1.
Dermed er gjennomsnittet, medianen og modusen henholdsvis lik:
3, 3 og 1
av Robson Luiz
Matematikklærer
I en gruppe mennesker er alderen: 10, 12, 15 og 17 år gammel. Hvis en 16-åring blir med i gruppen, hva skjer med gjennomsnittsalderen for gruppen?
Beregn gjennomsnittslønnen for det selskapet.