Når man får en prøve av størrelse n, beregnes prøvenes aritmetiske gjennomsnitt. Sannsynligvis, hvis en ny tilfeldig prøve blir tatt, vil det oppnådde aritmetiske gjennomsnittet være forskjellig fra det for den første prøven. Variasjonen av midler estimeres av deres standardfeil. Dermed evaluerer standardfeilen nøyaktigheten av beregningen av populasjonsgjennomsnittet.
Standardfeilen er gitt av formelen:
Hvor,
sx → er standardfeilen
s → er standardavviket
n → er prøvestørrelsen
Merk: Jo bedre presisjonen i beregningen av populasjonsgjennomsnittet er, desto mindre er standardfeilen.
Eksempel 1. I en populasjon ble det oppnådd et standardavvik på 2,64 med et tilfeldig utvalg på 60 elementer. Hva er den sannsynlige standardfeilen?
Løsning: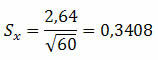
Dette indikerer at gjennomsnittet kan variere 0,3408 mer eller mindre.
Eksempel 2. I en populasjon ble det oppnådd et standardavvik på 1,32 med et tilfeldig utvalg på 121 elementer. Å vite at et gjennomsnitt på 6,25 ble oppnådd for samme prøve, bestemme den mest sannsynlige verdien for gjennomsnittet av dataene.
Løsning: For å bestemme den mest sannsynlige gjennomsnittsverdien av dataene må vi beregne standardfeilen i estimatet. Dermed vil vi ha:

Til slutt kan den mest sannsynlige verdien for gjennomsnittet av innhentede data representeres av:
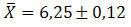
Ikke stopp nå... Det er mer etter annonseringen;)
Av Marcelo Rigonatto
Spesialist i statistikk og matematisk modellering
Brasil skolelag
Statistikk - Matte - Brasilskolen
Vil du referere til denne teksten i et skole- eller akademisk arbeid? Se:
RIGONATTO, Marcelo. "Standard estimatfeil"; Brasilskolen. Tilgjengelig i: https://brasilescola.uol.com.br/matematica/erro-padrao-estimativa.htm. Tilgang 27. juni 2021.