DE statistiek is het gebied van de wiskunde dat somt feiten en cijfers op waarin er een reeks methoden is waarmee we gegevens kunnen verzamelen en analyseren, waardoor het mogelijk wordt er enige interpretatie van te maken. De statistiek is opgedeeld in twee delen: beschrijvend en inferentieel. Beschrijvende statistiek wordt gekenmerkt door de organisatie, analyse en presentatie van gegevens, terwijl inferentiële statistieken dat wel hebben als kenmerk de studie van een steekproef van een bepaalde populatie en, op basis daarvan, het uitvoeren van analyses en de presentatie van Dobbelsteen.
Lees ook: Wat is de foutenmarge van een enquête?
Principes van statistiek
Vervolgens zullen we de belangrijkste concepten en principes van statistiek zien. Op basis daarvan kunnen meer geavanceerde concepten worden gedefinieerd.
bevolking of statistisch universum
De populatie of het statistische universum is de is set gevormd door alle elementen die deelnemen aan een bepaald onderzocht onderwerp.
Voorbeelden van statistisch universum
a) In een stad behoren alle inwoners tot het statistische universum.
b) Op een zeszijdige dobbelsteen wordt de populatie gegeven door het aantal gezichten.
{1, 2, 3, 4, 5, 6}
statistische gegevens
De statistische gegevens zijn een element dat tot de bevolking als geheel behoort, uiteraard moeten deze gegevens betrokken zijn bij het onderzoeksonderwerp.
Bevolking |
statistische gegevens |
zeszijdige dobbelstenen |
4 |
Braziliaanse Mountain Bike Kampioenen |
Henrique Avancini |
Monster
We noemen het monster de subset gevormd op basis van statistisch universum. Een steekproef wordt gebruikt wanneer de populatie erg groot of oneindig is. In gevallen waarin het verzamelen van alle informatie uit het statistische universum om financiële of logistieke redenen niet haalbaar is, is het ook noodzakelijk om steekproeven te gebruiken.
De keuze van een steekproef is uiterst belangrijk voor een enquête en moet de populatie betrouwbaar vertegenwoordigen. Een klassiek voorbeeld van het gebruik van steekproeven in een enquête is bij het uitvoeren van de demografische volkstelling van ons land.
Variabele
In statistiek is de variabele het object van studie, dat wil zeggen, het onderwerp dat het onderzoek wil bestuderen. Als je bijvoorbeeld de kenmerken van een stad bestudeert, kan het aantal inwoners een variabele zijn, evenals de hoeveelheid regen in een bepaalde periode of zelfs het aantal bussen voor transport openbaar. Merk op dat het concept van variabele in statistiek afhankelijk is van de onderzoekscontext.
De organisatie van gegevens in statistieken vindt plaats in fasen, zoals in elk organisatieproces. Eerst wordt het te onderzoeken onderwerp gekozen, vervolgens wordt de methode voor het verzamelen van de onderzoeksgegevens uitgedacht en de derde stap is het uitvoeren van de verzameling. Na het einde van deze laatste stap wordt de analyse uitgevoerd van wat is verzameld, en dus wordt op basis van de interpretatie gezocht naar resultaten. We zullen nu enkele belangrijke en noodzakelijke concepten voor gegevensorganisatie zien.
Niet stoppen nu... Er is meer na de reclame ;)
rol
In gevallen waarin de gegevens kunnen worden weergegeven door getallen, dat wil zeggen, wanneer de variabele kwantitatief is, wordt de lijst voor organisatie van deze gegevens. Een rooster kan oplopend of aflopend zijn. Als een variabele niet kwantitatief is, dat wil zeggen, als het kwalitatief is, is het niet mogelijk om de lijst te gebruiken, bijvoorbeeld als de gegevens gevoelens over een bepaald product zijn.
Voorbeeld
In een klaslokaal werden de lengtes van leerlingen in meters verzameld. Ze zijn: 1,70; 1,60; 1,65; 1,78; 1,71; 1,73; 1,72; 1,64.
Omdat de lijst oplopend of aflopend kan worden ingedeeld, volgt het volgende:
rol: (1,60; 1,64; 1,65; 1,70; 1,71; 1,72; 1,73; 1,78}
Merk op dat als de rol al gemonteerd is, het mogelijk is om een dobbelsteen gemakkelijker te vinden.
Frequentieverdelingstabel:
In gevallen waarin er veel elementen in de lijst zijn en veel herhalingen van gegevens, wordt de lijst verouderd, omdat de organisatie van deze gegevens onpraktisch is. In deze gevallen zijn de tabellen en de frequentieverdeling ze dienen als een uitstekend organisatorisch hulpmiddel.
In de distributietabel van absolute frequentie, we moeten de frequentie aangeven waarmee elke gegevens wordt weergegeven, dat wil zeggen het aantal keren dat ze verschijnen.
Laten we de distributietabel bouwen voor absolute frequentie de leeftijden, in jaren, van de leerlingen in een bepaalde klas.
Absolute frequentieverdeling | |
Leeftijd |
Frequentie (F) |
8 |
2 |
9 |
12 |
10 |
12 |
11 |
14 |
12 |
1 |
Totaal (FT) |
41 |
Uit de tabel kunnen we de volgende informatie halen: in de klas hebben we 2 leerlingen van 8, 12 9-jarige studenten, en nog 12 10-jarige studenten, enzovoort, met een totaal van 41 studenten. In de distributietabel van geaccumuleerde frequenties, moeten we de frequentie uit de vorige rij toevoegen (in de tabel met absolute frequentieverdeling).
Laten we de cumulatieve frequentieverdelingstabel bouwen voor leeftijden van dezelfde klasse als in het vorige voorbeeld, zie:
Geaccumuleerde frequentieverdeling | |
Leeftijd |
Frequentie (F) |
8 |
2 |
9 |
14 |
10 |
26 |
11 |
40 |
12 |
41 |
Totaal (FT) |
41 |
In de tafel van verdeling van relatieve frequenties, het percentage waarin elke gegevens voorkomt, wordt gebruikt. Opnieuw zullen we de berekeningen uitvoeren op basis van de tabel met absolute frequentieverdeling. We weten dat 41 overeenkomt met 100% van de leerlingen in de klas, dus om de percentage van elke leeftijd, delen we de frequentie van de leeftijd door 41 en vermenigvuldigen we het resultaat met 100, zodat we het als een percentage kunnen schrijven.
2: 41 = 0,048 · 100 → 4,8%
12: 41 = 0,292 · 100 → 29,2%
12: 41 = 0,292 · 100 → 29,2%
14: 41 = 0,341 · 100 → 34,1%
1: 41 = 0,024 · 100 → 2,4%
Relatieve frequentieverdeling | |
Leeftijd |
Frequentie (F) |
8 |
4,8% |
9 |
29,2% |
10 |
29,2% |
11 |
34,1% |
12 |
2,4% |
Totaal (FT) |
100% |
Lees ook:Toepassing van enstatistieken: ffrequentie Deabsoluut en frelatieve frequentie
Klassen
In gevallen waarin de variabele continu is, dat wil zeggen, wanneer deze meerdere waarden heeft, is het noodzakelijk om ze te groeperen in echte intervallen. In de statistiek worden deze intervallen klassen genoemd..
Om de tafel van te bouwen frequentieverdeling in klassen, we moeten de intervallen in de linkerkolom plaatsen, met hun juiste titel, en in de rechterkolom moeten we zet de absolute frequentie van elk van de intervallen, dat wil zeggen, hoeveel elementen bij elk horen hun.
Voorbeeld
Hoogte van studenten in het 3e jaar van de middelbare school op een school.
Frequentieverdeling in klassen | |
hoogte (meter) |
Absolute frequentie (F) |
[1,40; 1,50[ |
1 |
[1,50; 1,60[ |
4 |
[1,60; 1,70[ |
8 |
[1,70; 1,80[ |
2 |
[1,80; 1,90[ |
1 |
Totaal (FT) |
16 |
Als we de frequentieverdelingstabel in klassen analyseren, kunnen we zien dat we in de klas van het derde jaar 1 student hebben die een hoogte heeft tussen 1,40 m en 1,50 m, net zoals we 4 studenten hebben met een lengte tussen 1,50 en 1,60 m, en zo achtereenvolgens. We kunnen ook zien dat studenten een lengte hebben tussen 1,40 m en 1,90 m, het verschil tussen deze metingen, dat wil zeggen tussen de hoogste en de laagste hoogte van het monster, wordt genoemd amplitude.
Het verschil tussen de boven- en ondergrens van een klasse wordt de. genoemd klasse breedte, dus de tweede, die 4 studenten heeft met lengtes tussen 1,50 meter (meegeleverd) en 1,60 meter (niet inbegrepen), heeft een bereik van:
1,60 – 1,50
0,10 meter
Zie ook: Dispersiemaatregelen: amplitude en afwijking
positiemetingen
Positiemetingen worden gebruikt in gevallen waar het mogelijk is om een numerieke rol op te bouwen met de gegevens of een frequentietabel. Deze metingen geven de positie van de elementen ten opzichte van het rooster aan. De drie belangrijkste maten van positie zijn:
Gemiddelde
Beschouw de lijst met de elementen (a1, een2, een3, een4, …, DeNee), wordt het rekenkundig gemiddelde van deze n elementen gegeven door:
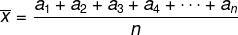
Voorbeeld
In een dansgroep werden de leeftijden van de leden verzameld en weergegeven in de volgende lijst:
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Laten we de gemiddelde leeftijd van de leden van deze dansgroep bepalen.
Volgens de formule moeten we alle elementen optellen en dit resultaat delen door het aantal elementen in de lijst, als volgt:
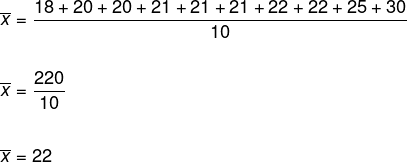
De gemiddelde leeftijd van de leden is dan ook 22 jaar.
Lees onze tekst voor meer informatie over deze positiemeting: Méochtend-.
mediaan-
De mediaan wordt gegeven door het centrale element van een rooster met een oneven aantal elementen. Als de lijst een even aantal elementen heeft, moeten we de twee centrale elementen beschouwen en het rekenkundig gemiddelde daartussen berekenen.
Voorbeeld
Beschouw de volgende lijst.
(2, 2, 3, 3,4, 5, 6, 7, 9)
Merk op dat element 4 de rol in twee gelijke delen verdeelt, dus het is het centrale element.
Voorbeeld
Bereken de gemiddelde leeftijd van de dansgroep.
Onthoud dat de lijst met leeftijden voor deze dansgroep wordt gegeven door:
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Merk op dat het aantal elementen in deze lijst gelijk is aan 10, dus het is niet mogelijk om de lijst in twee gelijke delen te verdelen. We moeten dus twee centrale elementen nemen en het rekenkundig gemiddelde van deze waarden uitvoeren.
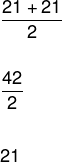
Zie meer details van deze positiemaatregel in onze tekst: Median.
Mode
We zullen mode het element van de rol noemen dat de hoogste frequentie heeft, dat wil zeggen het element dat er het meest in voorkomt.
Voorbeeld
Laten we de mode van de leeftijdsrol van de dansgroep bepalen.
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Het element dat het meest voorkomt is 21, dus de modus is gelijk aan 21.
Dispersie maatregelen
Dispersie maatregelen zijn: gebruikt in gevallen waarin het gemiddelde niet langer voldoende is. Stel je bijvoorbeeld voor dat twee auto's gemiddeld 40.000 kilometer hebben afgelegd. Alleen met kennis over gemiddelden kunnen we zeggen dat de twee auto's elk bepaalbare kilometers hebben gelopen, toch?
Stel je echter voor dat een van de auto's 79.000 kilometer heeft afgelegd en de andere 1.000 kilometers, let op dat alleen bij informatie over het gemiddelde geen uitspraken kunnen worden gedaan met precisie.
Bij verspreidingsmaatregelen zal ons vertellen hoe ver de elementen van een numerieke lijst verwijderd zijn van het rekenkundig gemiddelde. We hebben twee belangrijke spreidingsmaten:
Variantie (σ2)
Laten we het rekenkundig gemiddelde van de kwadraten van het verschil tussen elk element in de worp en het rekenkundig gemiddelde van die worp de variantie noemen. De variantie wordt weergegeven door: σ2.
Beschouw de lijst (x1, x2, x3, …, xNee) en dat het een rekenkundig gemiddelde heeftX. De variantie wordt gegeven door:
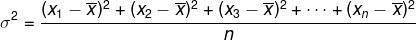
Standaarddeviatie (σ)
De standaarddeviatie wordt gegeven door de wortel van de variantie, het vertelt ons hoeveel een element is verspreid ten opzichte van het gemiddelde. De standaarddeviatie wordt aangegeven met σ.
Voorbeeld
Bepaal de standaarddeviatie van de dataset (4, 7, 10). Merk op dat hiervoor eerst de variantie moet worden bepaald en dat daarvoor eerst het gemiddelde van deze gegevens moet worden berekend.
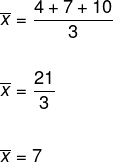
Als we deze gegevens in de variantieformule vervangen, hebben we:
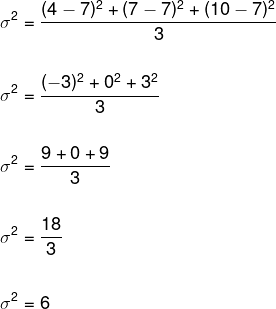
Om de standaarddeviatie te bepalen, moeten we de wortel van de variantie extraheren.
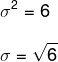
Lees verder: Dispersiematen: variantie en standaarddeviatie
Waar zijn statistieken voor?
We zagen dat de statistiek gerelateerd is aan: Problemen met tellen of gegevensorganisatie. Daarnaast speelt het een belangrijke rol bij de ontwikkeling van tools die het proces van het organiseren van gegevens, zoals tabellen, mogelijk maken. Statistieken zijn ook aanwezig in verschillende wetenschapsgebiedenOp basis van dataverzameling en -behandeling kan gewerkt worden met wiskundige modellen die verdere ontwikkeling in het onderzochte gebied mogelijk maken. Enkele gebieden waarop statistiek van fundamenteel belang is: economie, meteorologie, marketing, sport, sociologie en geowetenschappen.
In de meteorologie worden bijvoorbeeld gegevens in een bepaalde periode verzameld, nadat ze zijn georganiseerd, worden ze behandeld, en dus met op basis daarvan wordt een wiskundig model gebouwd dat ons in staat stelt om met een grotere mate van betrouwbaarheid. Statistiek is een tak van wetenschap waarmee we uitspraken kunnen doen met een zekere mate van betrouwbaarheid, maar nooit met 100% zekerheid.
Statistiek divisies
Statistiek is verdeeld in twee delen, beschrijvend en inferentieel. De eerste heeft betrekking op het tellen van de elementen die betrokken zijn bij het onderzoek, deze elementen worden één voor één geteld. Bij Beschrijvende statistieken, onze belangrijkste instrumenten zijn positiemetingen, zoals gemiddelde, mediaan en modus, evenals: spreidingsmaten zoals variantie en standaarddeviatie, we hebben ook frequentietabellen en grafiek.
Nog steeds in beschrijvende statistieken hebben we een zeer goed gedefinieerde methodologie voor a methodology presentatie van gegevens met een hoge mate van betrouwbaarheid die gaat door middel van organisatie en verzameling, samenvatting, interpretatie en representatie en, ten slotte, data-analyse. Een klassiek voorbeeld van het gebruik van beschrijvende statistieken komt voor in de volkstelling (elke 10 jaar) door het Braziliaanse Instituut voor Geografie en Statistiek (BIM).
DE inferentiële statistieken, op zijn beurt wordt het niet gekenmerkt door het één voor één verzamelen van gegevens van de elementen van een populatie, maar door het uitvoeren van de analyse van een steekproef van deze populatie, conclusies trekken over haar. In inferentiële statistieken moet voorzichtigheid worden betracht bij het kiezen van de steekproef, omdat deze de populatie zeer goed moet vertegenwoordigen. Sommige eerste resultaten, zoals middeling, in inferentiële statistieken die hoop worden genoemd, worden afgeleid op basis van kennis van beschrijvende statistieken.
Inferentiële statistieken worden bijvoorbeeld gebruikt in verkiezingspeilingen. Er wordt een steekproef uit de populatie gekozen, op een manier die deze representeert, en zo wordt het onderzoek uitgevoerd. Bij het kiezen van een steekproef die deze populatie niet goed vertegenwoordigt, zeggen we dat het onderzoek bevooroordeeld en dus onbetrouwbaar.
opgeloste oefeningen
vraag 1 – (U. F. Juiz de Fora – MG) Een natuurkundeleraar paste een test van 100 punten toe op zijn 22 studenten en behaalde als resultaat de verdeling van de cijfers, te zien in de volgende tabel:
40 |
20 |
10 |
20 |
70 |
60 |
90 |
80 |
30 |
50 |
50 |
70 |
50 |
20 |
50 |
50 |
10 |
40 |
30 |
20 |
60 |
60 |
– |
– |
Voer de volgende gegevensbehandelingen uit:
a) Schrijf de lijst van deze notities op.
b) Bepaal de relatieve frequentie van de hoogste noot.
Resolutie
a) Om de lijst van deze notities te maken, moeten we ze oplopend of aflopend schrijven. Dus we moeten:
10, 10, 20, 20, 20, 20, 30, 30, 40, 40, 50, 50, 50, 50, 50, 60, 60, 60, 80, 90
b) Als we naar de worp kijken, kunnen we zien dat de hoogste noot gelijk was aan 90 en dat de absolute frequentie gelijk is aan 1, aangezien deze maar één keer voorkomt. Om de relatieve frequentie te bepalen, moeten we de absolute frequentie van die noot delen door de totale frequentie, in dit geval gelijk aan 22. Dus:
relatieve frequentie
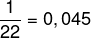
Om dit getal als een percentage door te geven, moeten we het met 100 vermenigvuldigen.
0,045 · 100
4,5%
Vraag 2 – (vijand) Na het rollen van een kubusvormige dobbelsteen met vlakken genummerd van 1 tot 6, 10 opeenvolgende keren, en noteer het aantal verkregen in elke zet, de volgende tabel met verdeling van frequenties.
Aantal verkregen |
Frequentie |
1 |
4 |
2 |
1 |
4 |
2 |
5 |
2 |
6 |
1 |
Het gemiddelde, de mediaan en de modus van deze frequentieverdeling zijn respectievelijk:
a) 3, 2 en 1
b) 3, 3 en 1
c) 3, 4 en 2
d) 5, 4 en 2
e) 6, 2 en 4
Resolutie
alternatief B.
Om het gemiddelde te bepalen, merk op dat er herhaling is van de verkregen getallen, dus we zullen het gewogen rekenkundig gemiddelde gebruiken.
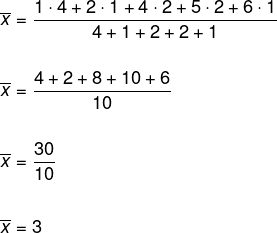
Om de mediaan te bepalen, moeten we het rooster oplopend of aflopend ordenen. Onthoud dat frequentie het aantal keren is dat het gezicht verschijnt.
1, 1, 1, 1, 2, 4, 4, 5, 5, 6
Omdat het aantal elementen in het rooster even is, moeten we het rekenkundig gemiddelde berekenen van de centrale elementen die het rooster in twee delen om de mediaan te bepalen, als volgt:
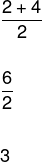
De modus wordt gegeven door het element dat het meest voorkomt, dat wil zeggen, het heeft de hoogste frequentie, dus we hebben dat de modus gelijk is aan 1.
Het gemiddelde, de mediaan en de modus zijn dus respectievelijk gelijk aan:
3, 3 en 1
door Robson Luiz
Wiskundeleraar
In een groep mensen zijn de leeftijden: 10, 12, 15 en 17 jaar. Als een 16-jarige zich bij de groep aansluit, wat gebeurt er dan met de gemiddelde leeftijd van de groep?
Bereken het gemiddelde salaris voor dat bedrijf.