DE statistisk är fältet matematik det listar fakta och siffror där det finns en uppsättning metoder som gör det möjligt för oss att samla in data och analysera dem, vilket gör det möjligt att utföra en viss tolkning av dem. Statistiken är uppdelad i två delar: beskrivande och inferentiell. Beskrivande statistik kännetecknas av organisering, analys och presentation av data, medan inferentiell statistik har som en egenskap att studera ett urval av en viss population och, baserat på det, analysens genomförande och presentation av Tärningar.
Läs också: Vad är en enkäts felmarginal?
Principer för statistik
Därefter ser vi de viktigaste begreppen och principerna för statistik. Baserat på dem kommer det att vara möjligt att definiera mer sofistikerade koncept.
befolkning eller statistiska universum
Befolkningen eller det statistiska universum är uppsättning bildad av alla element som deltar i ett särskilt forskat ämne.
Exempel på statistiska universum
a) I en stad tillhör alla invånare det statistiska universum.
b) På en sexsidig dör ges befolkningen av antalet ansikten.
{1, 2, 3, 4, 5, 6}
statistisk data
De statistiska uppgifterna är en element som tillhör befolkningen som helhet, uppenbarligen måste dessa data vara inblandade i forskningstemat.
Befolkning |
statistisk data |
sexsidig tärning |
4 |
Brasilianska mästare på mountainbike |
Henrique Avancini |
Prov
Vi kallar provet delmängd bildat baserat på det statistiska universum. Ett urval används när befolkningen är mycket stor eller oändlig. I fall där det är omöjligt att samla all information från det statistiska universum av ekonomiska eller logistiska skäl är det också nödvändigt att använda prover.
Valet av ett urval är extremt viktigt för en undersökning och det måste representera befolkningen på ett tillförlitligt sätt. Ett klassiskt exempel på användningen av prover i en undersökning är att genomföra demografiska folkräkningen i vårt land.
Variabel
I statistiken är variabeln föremål för studier, det vill säga ämnet som forskningen avser att studera. När man till exempel studerar stadens egenskaper kan antalet invånare vara en variabel, samt volymen regn under en viss period eller till och med antalet bussar för transport offentlig. Observera att begreppet variabel i statistik är beroende av forskningssammanhang.
Organiseringen av data i statistiken sker i faser, som i alla organisationsprocesser. Inledningsvis väljs ämnet som ska undersökas, sedan tänks metoden för att samla in forskningsdata och det tredje steget är att genomföra insamlingen. Efter slutet av detta sista steg utförs analysen av vad som samlats in och därför söks resultat baserat på tolkningen. Vi kommer nu att se några viktiga och nödvändiga begrepp för dataorganisation.
Sluta inte nu... Det finns mer efter reklam;)
roll
I de fall där data kan representeras av siffror, det vill säga när variabeln är kvantitativ, listan för organisation av dessa uppgifter. En lista kan vara stigande eller fallande. Om en variabel inte är kvantitativ, det vill säga om den är kvalitativ, är det inte möjligt att använda listan, till exempel om data är känslor för en viss produkt.
Exempel
I ett klassrum samlades elevernas höjder i meter. De är: 1,70; 1,60; 1,65; 1,78; 1,71; 1,73; 1,72; 1,64.
Eftersom listan kan ordnas stigande eller fallande följer följande:
rol: (1,60; 1,64; 1,65; 1,70; 1,71; 1,72; 1,73; 1,78}
Observera att, med rullen redan monterad, är det möjligt att hitta data lättare.
Frekvensfördelningstabell
I de fall där det finns många element i listan och många upprepningar av data blir listan föråldrad, eftersom organisationen av dessa data är omöjlig. I dessa fall borden och frekvensfördelning de fungerar som ett utmärkt organisatoriskt verktyg.
I distributionstabellen för absolut frekvens, vi måste ange frekvensen vid vilken varje data visas, det vill säga hur många gånger den visas.
Låt oss bygga distributionstabellen för absolut frekvens åldrarna, i år, för eleverna i en given klass.
Absolut frekvensfördelning | |
Ålder |
Frekvens (F) |
8 |
2 |
9 |
12 |
10 |
12 |
11 |
14 |
12 |
1 |
Totalt (FT) |
41 |
Från tabellen kan vi få följande information: i klassen har vi 2 elever i åldern 8, 12 9-åriga studenter och 12 fler 10-åriga studenter, och så vidare, når totalt 41 studenter. I distributionstabellen för ackumulerade frekvensermåste vi lägga till frekvensen från föregående rad (i den absoluta frekvensfördelningstabellen).
Låt oss bygga den kumulativa frekvensfördelningstabellen för åldrar av samma klass som i föregående exempel, se:
Ackumulerad frekvensfördelning | |
Ålder |
Frekvens (F) |
8 |
2 |
9 |
14 |
10 |
26 |
11 |
40 |
12 |
41 |
Totalt (FT) |
41 |
I tabellen över fördelning av relativa frekvenser, den procentandel där varje data visas används. Återigen kommer vi att göra beräkningarna baserat på den absoluta frekvensfördelningstabellen. Vi vet att 41 motsvarar 100% av eleverna i klassen, så för att bestämma procentsats i varje ålder delar vi bara åldersfrekvensen med 41 och multiplicerar resultatet med 100 så att vi kan skriva det i procent.
2: 41 = 0,048 · 100 → 4,8%
12: 41 = 0,292 · 100 → 29,2%
12: 41 = 0,292 · 100 → 29,2%
14: 41 = 0,341 · 100 → 34,1%
1: 41 = 0,024 · 100 → 2,4%
Relativ frekvensfördelning | |
Ålder |
Frekvens (F) |
8 |
4,8% |
9 |
29,2% |
10 |
29,2% |
11 |
34,1% |
12 |
2,4% |
Totalt (FT) |
100% |
Läs också:Tillämpning av ochstatistik: ffrekvens Deabsolut och frelativ frekvens
Klasser
I fall där variabeln är kontinuerlig, det vill säga när den har flera värden, är det nödvändigt att gruppera dem verkliga intervall. I statistiken kallas dessa intervall för klasser..
Att bygga bordet av frekvensfördelning i klasser, vi måste placera intervallen i den vänstra kolumnen, med deras rätta titel, och i den högra kolumnen måste vi sätt den absoluta frekvensen för vart och ett av intervallen, det vill säga hur många element som tillhör var och en deras.
Exempel
Studenternas höjd på gymnasiet på en tredje skola.
Frekvensfördelning i klasser | |
höjd (meter) |
Absolut frekvens (F) |
[1,40; 1,50[ |
1 |
[1,50; 1,60[ |
4 |
[1,60; 1,70[ |
8 |
[1,70; 1,80[ |
2 |
[1,80; 1,90[ |
1 |
Totalt (FT) |
16 |
Genom att analysera frekvensfördelningstabellen i klasser kan vi se att vi i tredje årsklassen har 1 student som har en höjd mellan 1,40 m och 1,50 m, precis som vi har 4 elever med en höjd mellan 1,50 och 1,60 m, och så successivt. Vi kan också observera att eleverna har höjder mellan 1,40 m och 1,90 m, skillnaden mellan dessa mätningar, det vill säga mellan provets högsta och lägsta höjd, kallas amplitud.
Skillnaden mellan klassens övre och nedre gräns kallas klassbreddSåledes har den andra, som har 4 elever med höjder mellan 1,50 meter (ingår) och 1,60 meter (ingår ej), en räckvidd på:
1,60 – 1,50
0,10 meter
Se också: Dispersionsmått: amplitud och avvikelse
positionsmätningar
Positionsmått används i fall där det är möjligt att bygga en numerisk rulle med data eller en frekvenstabell. Dessa mätningar indikerar elementens position i förhållande till listan. De tre huvudmåtten för position är:
Genomsnitt
Tänk på listan med elementen (a1, a2, a3, a4,..., TheNej), det aritmetiska medelvärdet av dessa n-element ges av:
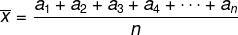
Exempel
I en dansgrupp samlades medlemmarnas åldrar och representerades i följande lista:
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Låt oss bestämma medelåldern för medlemmarna i den här dansgruppen.
Enligt formeln måste vi lägga till alla element och dela detta resultat med antalet element i listan, så här:
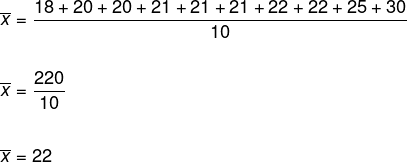
Medlemmarnas medelålder är därför 22 år gammal.
För att lära dig mer om denna positionsmätning, läs vår text: Mémorgon-.
median
Medianen ges av det centrala elementet i en lista som har ett udda antal element. Om listan har ett jämnt antal element måste vi ta hänsyn till de två centrala elementen och beräkna det aritmetiska medelvärdet mellan dem.
Exempel
Tänk på följande lista.
(2, 2, 3, 3,4, 5, 6, 7, 9)
Observera att element 4 delar upp rollen i två lika delar, så det är det centrala elementet.
Exempel
Beräkna medianåldern för dansgruppen.
Kom ihåg att listan över åldrar för denna dansgrupp ges av:
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Observera att antalet element i denna lista är lika med 10, så det är inte möjligt att dela listan i två lika delar. Så vi måste ta två centrala element och utföra det aritmetiska medelvärdet av dessa värden.
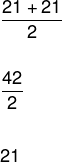
Se mer information om denna positionsmått i vår text: Median.
Mode
Vi kommer att kalla mode det element i den roll som har den högsta frekvensen, det vill säga det element som visas mest i det.
Exempel
Låt oss bestämma mode för dansgruppens åldersrulle.
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Det element som visas mest är 21, så läget är lika med 21.
Dispersionsåtgärder
Dispersionsåtgärder är används i fall där genomsnittet inte längre är tillräckligt. Föreställ dig till exempel att två bilar i genomsnitt har täckt 40 000 kilometer. Bara med kunskap om genomsnitt kan vi säga att de två bilarna gick bestämbara kilometer vardera, eller hur?
Föreställ dig dock att en av bilarna har täckt 79 000 kilometer och den andra 1000 kilometer, notera att endast med information om genomsnittet är det inte möjligt att göra uttalanden med precision.
På spridningsåtgärder kommer att berätta hur långt elementen i en numerisk lista är från det aritmetiska medelvärdet. Vi har två viktiga mått på spridning:
Varians (σ2)
Låt oss kalla det aritmetiska medelvärdet av kvadraterna av skillnaden mellan varje element i rullen och det aritmetiska medelvärdet för den rullen som varians. Variansen representeras av: σ2.
Tänk på listan (x1, x2, x3,..., xNej) och att det har aritmetiskt medelvärdex. Variansen ges av:
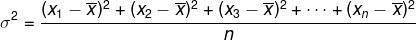
Standardavvikelse (σ)
Standardavvikelsen ges av varianternas rot, den berättar hur mycket ett element är spridd i förhållande till medelvärdet. Standardavvikelsen betecknas med σ.
Exempel
Bestäm standardavvikelsen för datamängden (4, 7, 10). Observera att för detta är det nödvändigt att bestämma variansen först, och att, för det, är det nödvändigt att först beräkna genomsnittet av dessa data.
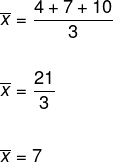
Vi ersätter dessa data i variansformeln:
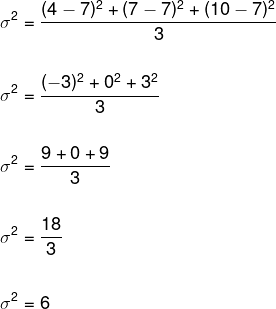
För att bestämma standardavvikelsen måste vi extrahera roten till variansen.
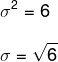
Läs mer: Dispersionsmått: varians och standardavvikelse
Vad är statistik för?
Vi såg att statistiken är relaterad till Räkne- eller dataorganisationsproblem. Dessutom har den en viktig roll i utvecklingen av verktyg som möjliggör dataorganisationsprocessen, till exempel i tabeller. Statistik finns också i olika vetenskapsområden, baserat på datainsamling och behandling, är det möjligt att arbeta med matematiska modeller som möjliggör vidare utveckling inom det studerade området. Vissa områden där statistik är grundläggande: ekonomi, meteorologi, marknadsföring, sport, sociologi och geovetenskap.
I meteorologi, till exempel, samlas data in under en viss period, efter att ha organiserats, behandlas de, och så med baserat på dem byggs en matematisk modell som gör att vi kan hävda om klimatet från tidigare dagar med större grad av pålitlighet. Statistik är en gren av vetenskapen som tillåter oss att göra uttalanden med viss grad av tillförlitlighet, men aldrig 100% säkerhet.
Statistiska uppdelningar
Statistik är uppdelad i två delar, beskrivande och inferentiell. Den första är relaterad till att räkna de element som är inblandade i forskningen, dessa element räknas en efter en. På Beskrivande statistik, våra huvudsakliga verktyg är positionsmått, som medelvärde, median och läge samt dispersionsmått som varians och standardavvikelse har vi också frekvenstabeller och grafik.
Fortfarande i beskrivande statistik har vi en väldefinierad metod för a presentation av data med en avsevärd grad av tillförlitlighet som går igenom organisation och insamling, sammanfattning, tolkning och representation och slutligen dataanalys. Ett klassiskt exempel på användning av beskrivande statistik förekommer i folkräkningen (vart tionde år) av det brasilianska institutet för geografi och statistik (IBGE).
DE inferentiell statistik, i sin tur kännetecknas det inte av att samla in data från elementen i en befolkning en efter en utan genom att utföra analys av ett urval av denna population, som drar slutsatser om henne. I inferentiell statistik måste man vara försiktig när man väljer urvalet, eftersom det måste representera befolkningen mycket bra. Några initiala resultat, såsom medelvärde, i slutsatsstatistik som kallas hopp, härleds utifrån kunskap om beskrivande statistik.
Inferentiell statistik används till exempel i valundersökningar. Ett urval av befolkningen väljs, på ett sätt som representerar den, och därmed genomförs forskningen. När vi väljer ett urval som inte representerar denna population särskilt bra säger vi att forskningen är det partisk och därför opålitliga.
lösta övningar
fråga 1 - (U. F. Juiz de Fora - MG) En fysiklärare tillämpade ett test, värt 100 poäng, på sina 22 elever och fick, som ett resultat, fördelningen av betyg, se i följande tabell:
40 |
20 |
10 |
20 |
70 |
60 |
90 |
80 |
30 |
50 |
50 |
70 |
50 |
20 |
50 |
50 |
10 |
40 |
30 |
20 |
60 |
60 |
– |
– |
Utför följande databehandlingar:
a) Skriv listan över dessa anteckningar.
b) Bestäm den relativa frekvensen för den högsta tonen.
Upplösning
a) För att göra listan över dessa anteckningar måste vi skriva dem på stigande eller fallande sätt. Så vi måste:
10, 10, 20, 20, 20, 20, 30, 30, 40, 40, 50, 50, 50, 50, 50, 60, 60, 60, 80, 90
b) När vi tittar på rullen kan vi se att den högsta tonen var lika med 90 och att dess absoluta frekvens är lika med 1, eftersom den bara visas en gång. För att bestämma den relativa frekvensen måste vi dela den absoluta frekvensen för den noten med den totala frekvensen, i detta fall lika med 22. Således:
relativ frekvens
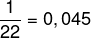
För att skicka detta nummer i procent måste vi multiplicera det med 100.
0,045 · 100
4,5%
Fråga 2 - (Enem) Efter att ha rullat en kubformad form med ansikten numrerade från 1 till 6, tio gånger i rad, och notera antalet som erhållits i varje drag, följande fördelningstabell för frekvenser.
Antal erhållet |
Frekvens |
1 |
4 |
2 |
1 |
4 |
2 |
5 |
2 |
6 |
1 |
Medelvärdet, medianen och läget för denna frekvensfördelning är respektive:
a) 3, 2 och 1
b) 3, 3 och 1
c) 3, 4 och 2
d) 5, 4 och 2
e) 6, 2 och 4
Upplösning
Alternativ B.
För att bestämma medelvärdet, notera att det finns repetition av de erhållna siffrorna, så vi kommer att använda det viktade aritmetiska medelvärdet.
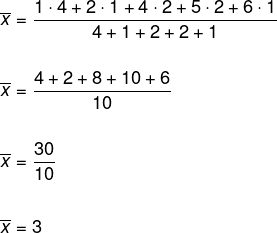
För att bestämma medianen måste vi ordna listan på stigande eller fallande sätt. Kom ihåg att frekvensen är det antal gånger ansiktet dyker upp.
1, 1, 1, 1, 2, 4, 4, 5, 5, 6
Eftersom antalet element i listan är jämnt måste vi beräkna det aritmetiska medelvärdet av de centrala elementen som delar listan i hälften för att bestämma medianen, så här:
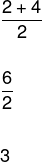
Läget ges av det element som verkar mest, det vill säga det har den högsta frekvensen, så vi har att läget är lika med 1.
Således är medelvärdet, medianen och läget, respektive lika med:
3, 3 och 1
av Robson Luiz
Mattelärare
I en grupp människor är åldrarna: 10, 12, 15 och 17 år. Om en 16-åring går med i gruppen, vad händer med medelåldern för gruppen?
Beräkna den genomsnittliga lönen för det företaget.