
korelácia znamená podobnosť resp vzťah medzi dvoma vecami, ľuďmi alebo myšlienkami. Ide o podobnosť alebo rovnocennosť, ktorá existuje medzi dvoma rôznymi hypotézami, situáciami alebo objektmi.
V oblasti štatistiky a matematiky sa koreláciou rozumie miera medzi dvoma alebo viacerými premennými, ktoré spolu súvisia.
Termín korelácia je ženské podstatné meno, ktoré pochádza z latinčiny korelovať.
Slovo korelácia môže byť nahradené synonymami ako: vzťah, ekvivalencia, spojitosť, korešpondencia, analógia a spojitosť.
Korelačný koeficient
V štatistikách Pearsonov korelačný koeficient (r), ktorý sa tiež nazýva korelačný koeficient produkt-hybnosť, meria vzťah, ktorý existuje medzi dvoma premennými v rámci tej istej metrickej škály.
Funkciou korelačného koeficientu je určiť silu vzťahu, ktorý existuje medzi množinami známych údajov alebo informácií.
Hodnota korelačného koeficientu sa môže pohybovať medzi -1 a 1 a získaný výsledok určuje, či je korelácia negatívna alebo pozitívna.
Na interpretáciu koeficientu je potrebné vedieť, že 1 znamená, že korelácia medzi premennými je
perfektné pozitívum a -1 znamená, že je dokonalý zápor. Ak je koeficient rovný 0, znamená to, že premenné na sebe nezávisia.V štatistikách existuje aj Spearmanov korelačný koeficient, pomenovaná podľa štatistika Charlesa Spearmana. Funkciou tohto koeficientu je zmerať intenzitu vzťahu medzi dvoma premennými, či už sú lineárne alebo nie.
Spearmanova korelácia slúži na posúdenie, či je intenzita vzťahu medzi dvoma analyzovanými premennými možno merať monotónnou funkciou (matematická funkcia, ktorá zachováva alebo invertuje poradový vzťah počiatočné).
Výpočet Pearsonovho korelačného koeficientu
Metóda 1) Výpočet Pearsonovho korelačného koeficientu pomocou kovariancie a štandardnej odchýlky.
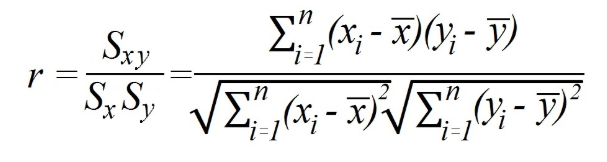
Kde
sXYje kovariancia;
sX a srpredstavujú smerodajnú odchýlku premenných xay.
V tomto prípade výpočet zahŕňa najskôr nájdenie kovariancie medzi premennými a štandardnej odchýlky každej z nich. Potom vydeľte kovarianciu vynásobením štandardných odchýlok.
Výrok už často poskytuje buď štandardné odchýlky premenných, alebo kovarianciu medzi nimi, a to iba pomocou vzorca.
Metóda 2) Výpočet Pearsonovho korelačného koeficientu so surovými údajmi (bez kovariancie alebo štandardnej odchýlky).
Pri tejto metóde je najpriamejší vzorec nasledovný:
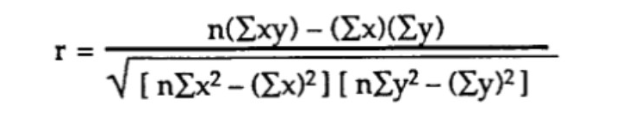
Napríklad za predpokladu, že máme údaje s n = 6 pozorovaniami dvoch premenných: hladina glukózy (y) a vek (x), výpočet sa riadi týmito krokmi:
Krok 1) Vytvorte tabuľku s existujúcimi údajmi: i, x, y a pridajte prázdne stĺpce pre xy, x² a y²:
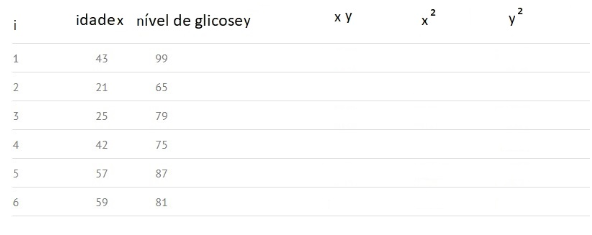
Krok 2: Vynásobte x a y, aby ste vyplnili stĺpec „xy“. Napríklad v riadku 1 budeme mať: x1y1 = 43 × 99 = 4257.

Krok 3: Zarovnajte hodnoty v stĺpci x a výsledky zaznamenajte do stĺpca x². Napríklad v prvom riadku budeme mať x12 = 43 × 43 = 1849.

Krok 4: Postupujte rovnako ako v kroku 3, teraz použite stĺpec y a do stĺpca y² zaznamenajte štvorček svojich hodnôt. Napríklad v prvom riadku budeme mať: y12 = 99 × 99 = 9801.

Krok 5: Získajte súčet všetkých čísel stĺpcov a výsledok vložte do päty stĺpca. Napríklad súčet stĺpca Vek X sa rovná 43 + 21 + 25 + 42 + 57 + 59 = 247.

Krok 6: Použite vyššie uvedený vzorec na získanie korelačného koeficientu:

Takže máme:

Výpočet Spearmanovho korelačného koeficientu
Výpočet Spearmanovho korelačného koeficientu je trochu odlišný. Za týmto účelom musíme usporiadať naše údaje v nasledujúcej tabuľke:
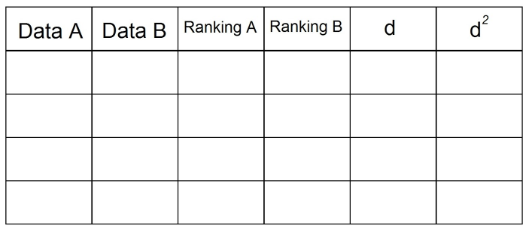
1. Keď máme vo výpise 2 páry dát, musíme ich uviesť v tabuľke. Napríklad:
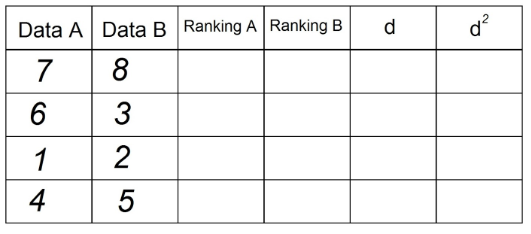
2. V stĺpci „Poradie A“ zoradíme pozorovania, ktoré sú v „dátume A“ vzostupne „1“ najnižšia hodnota v stĺpci a n (celkový počet pozorovaní) najvyššia hodnota v stĺpci „Dátum“ ". V našom príklade je to:
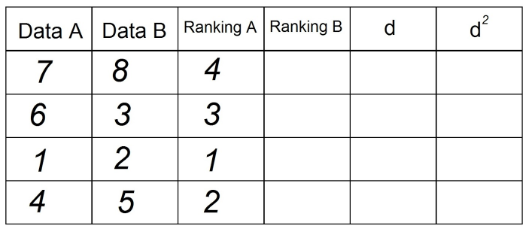
3. To isté urobíme pre získanie stĺpca „Poradie B“, pričom teraz použijeme pozorovania v stĺpci „Údaje B“:
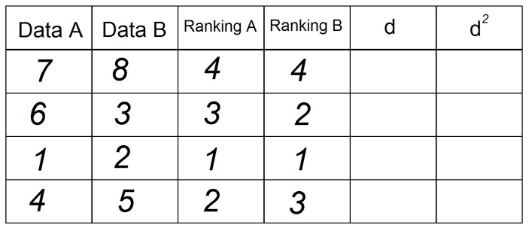
4. Do stĺpca „d“ dáme rozdiel medzi dvoma rebríčkami (A - B). Tu na signále nezáleží.

5. Každú z hodnôt v stĺpci „d“ zarovnajte na druhú a zaznamenajte do stĺpca d²:
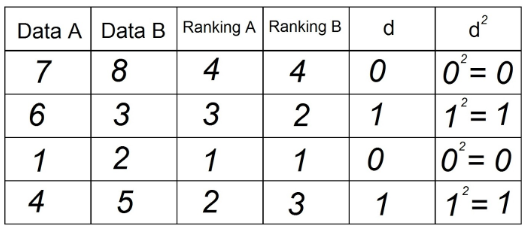
6. Sčítajte všetky údaje zo stĺpca „d²“. Táto hodnota je ²d². V našom príklade Σd² = 0 + 1 + 0 + 1 = 2
7. Teraz použijeme Spearmanov vzorec:
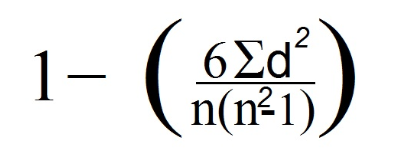
V našom prípade sa n rovná 4, keď sa pozrieme na počet dátových riadkov (čo zodpovedá počtu pozorovaní).
8. Nakoniec sme nahradili údaje v predchádzajúcom vzorci:
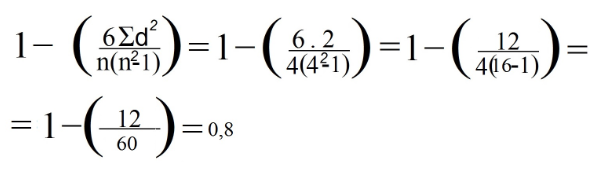
lineárna regresia
Lineárna regresia je vzorec, ktorý sa používa na odhad možnej hodnoty premennej (y), keď sú známe hodnoty iných premenných (x). Hodnota „x“ je nezávislá alebo vysvetľujúca premenná a „y“ je závislá premenná alebo odpoveď.
Lineárna regresia sa používa na zistenie toho, ako sa môže hodnota „y“ meniť v závislosti od premennej „x“. Riadok obsahujúci hodnoty kontroly odchýlky sa nazýva lineárna regresná čiara.
Ak má vysvetľujúca premenná "x" jednu hodnotu, bude sa volať regresia jednoduchá lineárna regresia.
