Statistik er området Matematik, der studerer indsamling, registrering, organisering og analyse af forskningsdata.
Dette emne debiteres i mange konkurrencer. Så udnyt de kommenterede og løste øvelser for at løse al din tvivl.
Kommenterede og løste problemer
1) Enem - 2017
Præstationsevalueringen af studerende på et universitetskursus er baseret på det vægtede gennemsnit af karaktererne opnået i fagene med det respektive antal point, som vist i tabellen:

Jo bedre vurderingen af en studerende i et givet akademisk semester er, desto større prioritet har han til valg af emner til næste semester.
En bestemt elev ved, at hvis han opnår en “God” eller “Fremragende” vurdering, vil han være i stand til at tilmelde sig de emner, han ønsker. Han har allerede taget prøverne for 4 af de 5 fag, han er tilmeldt, men han har endnu ikke taget testen for fag I, som vist i tabellen.
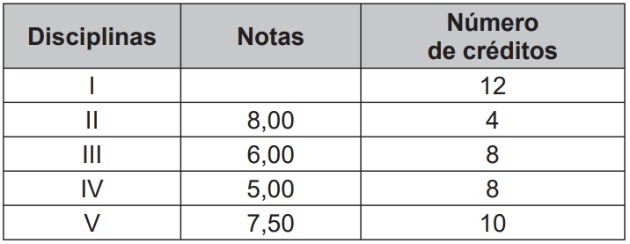
For at han kan nå sit mål, er den mindstekarakter, han skal opnå i fag I
a) 7.00.
b) 7.38.
c) 7,50.
d) 8,25.
e) 9.00.
For at beregne det vægtede gennemsnit multiplicerer vi hver karakter med sit respektive antal point, tilføjer derefter alle fundne værdier og deler til sidst med det samlede antal point.
Gennem den første tabel identificerer vi, at den studerende skal nå mindst et gennemsnit svarende til 7 for at opnå den "gode" evaluering. Derfor skal det vægtede gennemsnit være lig med denne værdi.
Når vi kalder den manglende note af x, skal vi løse følgende ligning:
Alternativ: d) 8.25
2) Enem - 2017
Tre studerende, X, Y og Z, er tilmeldt et engelsk kursus. For at vurdere disse studerende valgte læreren at tage fem prøver. For at bestå dette kursus skal den studerende have det aritmetiske gennemsnit af karaktererne for de fem prøver, der er større end eller lig med 6. I tabellen vises de noter, som hver elev tog i hver test.
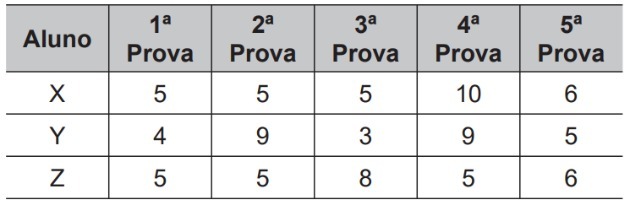
Baseret på tabeldataene og de givne oplysninger vil du mislykkes
a) kun studerende Y.
b) kun studerende Z.
c) kun studerende X og Y.
d) kun studerende X og Z.
e) studerende X, Y og Z.
Det aritmetiske gennemsnit beregnes ved at tilføje alle værdierne og dividere med antallet af værdier. Lad os i dette tilfælde tilføje hver studerendes karakterer og dele med fem.
Da den studerende vil bestå en karakter, der er lig med eller større end 6, vil de studerende X og Y bestå, og student Z ikke bestå.
Alternativ: b) kun studerende Z.
3) Enem - 2017
Grafen viser arbejdsløshedsgraden (i%) for perioden fra marts 2008 til april 2009, opnået på baggrund af data observeret i hovedstadsregionerne Recife, Salvador, Belo Horizonte, Rio de Janeiro, São Paulo og Porto Lykkelig.
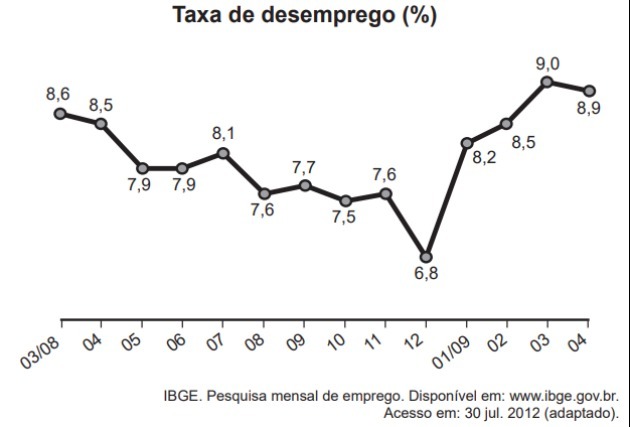
Medianen for denne ledighed i perioden fra marts 2008 til april 2009 var
a) 8,1%
b) 8,0%
c) 7,9%
d) 7,7%
e) 7,6%
For at finde medianværdien skal vi starte med at sætte alle værdier i rækkefølge. Vi identificerer derefter den position, der deler området i to med det samme antal værdier.
Når antallet af værdier er ulige, er medianen det tal, der er nøjagtigt midt i området. Når det er jævnt, er medianen lig med det aritmetiske gennemsnit af de to centrale værdier.
Overholdende grafen identificerer vi, at der er 14 værdier relateret til ledigheden. Da 14 er et lige tal, vil medianen være lig med det aritmetiske gennemsnit mellem den 7. værdi og den 8. værdi.
På denne måde kan vi sætte tallene i rækkefølge, indtil vi når disse positioner som vist nedenfor:
6,8; 7,5; 7,6; 7,6; 7,7; 7,9; 7,9; 8,1
Beregning af gennemsnittet mellem 7,9 og 8,1 har vi:
Alternativ: b) 8,0%
4) Fuvest - 2016
Et køretøj kører mellem to byer i Serra da Mantiqueira og dækker den første tredjedel af byen rute med en gennemsnitlig hastighed på 60 km / t, den næste tredjedel ved 40 km / t og resten af ruten ved 20 km / t. Den værdi, der bedst tilnærmer køretøjets gennemsnitlige hastighed på denne tur, i km / t, er
a) 32,5
b) 35
c) 37,5
d) 40
e) 42,5
Vi er nødt til at finde middelhastighedsværdien og ikke gennemsnittet af hastighederne. I dette tilfælde kan vi ikke beregne det aritmetiske gennemsnit, men det harmoniske gennemsnit.
Vi bruger det harmoniske gennemsnit, når de involverede størrelser er omvendt proportionale, som det er tilfældet med hastighed og tid.
Det harmoniske gennemsnit er det omvendte af det aritmetiske gennemsnit af værdiernes inverser, vi har:
Derfor er den nærmeste værdi i svarene 32,5 km / t
Alternativ: a) 32.5
5) Enem - 2015
I en selektiv til finalen på 100 meter freestyle svømning i et OL opnåede atleterne i deres respektive baner følgende tidspunkter:

Mediantiden vist i tabellen er
a) 20.70.
b) 20,77.
c) 20.80.
d) 20,85.
e) 20.90.
Lad os først sætte alle værdier, inklusive gentagne tal, i stigende rækkefølge:
20,50; 20,60; 20,60; 20,80; 20,90; 20,90; 20,90; 20,96
Bemærk, at der er et lige antal værdier (8 gange), så medianen er det aritmetiske gennemsnit mellem værdien, der er i 4. position og den i 5. position:
Alternativ: d) 20.85.
6) Enem - 2014
Kandidaterne K, L, M, N og P konkurrerer om en enkelt jobåbning i en virksomhed og har taget prøver i portugisisk, matematik, jura og IT. Tabellen viser scoringer opnået af de fem kandidater.
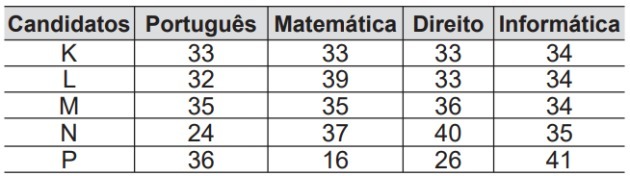
I henhold til udvælgelsesmeddelelsen er den succesrige kandidat den, for hvem medianen for de karakterer, han opnår i de fire fag, er den højeste. Den succesrige kandidat vil være
a) K.
b) L.
c)
d) Nej
e) Q
Vi skal finde hver kandidats median for at identificere, hvilken der er den højeste. Lad os derfor sætte hver enkelt karakter i orden og finde medianen.
Kandidat K:
Kandidat L:
Kandidat M:
Kandidat N:
Kandidat P:
Alternativ: d) N
Se også Matematik i fjende og Matematikformler
7) Fuvest - 2015
Undersøg diagrammet.
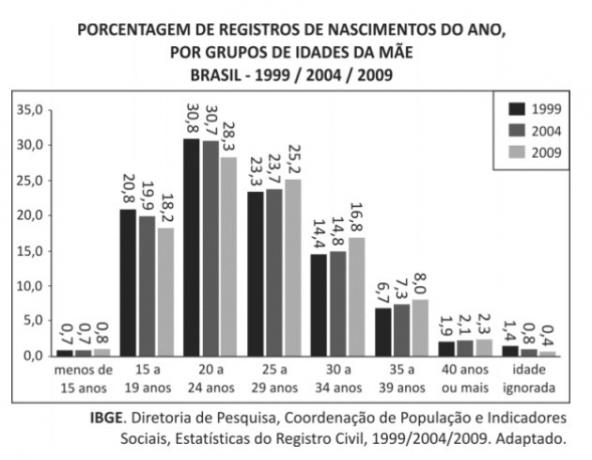
Baseret på dataene i grafen kan det angives korrekt, at alder
a) medianen for mødre til børn født i 2009 var større end 27 år.
b) medianen for mødre til børn født i 2009 var mindre end 23 år.
c) medianen for mødre til børn født i 1999 var større end 25 år.
d) middelværdien af mødre til børn født i 2004 var større end 22 år.
e) middelværdien af mødre til børn født i 1999 var mindre end 21 år.
Lad os starte med at identificere i hvilket område medianen for mødre til børn født i 2009 er placeret (lysegrå bjælker).
Til dette vil vi overveje, at middelalderen for aldre er placeret på det punkt, hvor frekvensen tilføjer op til 50% (midt i området).
På denne måde beregner vi de akkumulerede frekvenser. I nedenstående tabel angiver vi frekvenserne og de kumulative frekvenser for hvert interval:
| aldersgrupper | Frekvens | Kumulativ frekvens |
| under 15 år | 0,8 | 0,8 |
| 15 til 19 år gammel | 18,2 | 19,0 |
| 20 til 24 år | 28,3 | 47,3 |
| 25 til 29 år gammel | 25,2 | 72,5 |
| 30 til 34 år gammel | 16,8 | 89,3 |
| 35 til 39 år gammel | 8,0 | 97,3 |
| 40 år eller mere | 2,3 | 99,6 |
| ignoreret alder | 0,4 | 100 |
Bemærk, at det kumulative fremmøde når 50% i intervallet 25 til 29 år. Derfor er bogstaverne a og b forkerte, da de angiver værdier uden for dette interval.
Vi bruger den samme procedure til at finde medianen fra 1999. Data er i nedenstående tabel:
| aldersgrupper | Frekvens | Kumulativ frekvens |
| under 15 år | 0,7 | 0,7 |
| 15 til 19 år gammel | 20,8 | 21,5 |
| 20 til 24 år | 30,8 | 52,3 |
| 25 til 29 år gammel | 23,3 | 75,6 |
| 30 til 34 år gammel | 14,4 | 90,0 |
| 35 til 39 år gammel | 6,7 | 96,7 |
| 40 år eller mere | 1,9 | 98,6 |
| ignoreret alder | 1,4 | 100 |
I denne situation forekommer medianen i intervallet 20 til 24 år. Derfor er bogstavet c også forkert, da det præsenterer en mulighed, der ikke hører til området.
Lad os nu beregne gennemsnittet. Denne beregning udføres ved at tilføje frekvensprodukterne med intervallets gennemsnitsalder og dividere værdien fundet med summen af frekvenserne.
Til beregningen vil vi se bort fra de værdier, der er relateret til intervallerne "under 15 år", "40 år eller derover" og "ignoreret alder".
Når vi tager værdierne af grafen for året 2004, har vi således følgende gennemsnit:
Selv hvis vi havde overvejet de ekstreme værdier, ville gennemsnittet være større end 22 år. Så udsagnet er sandt.
Bare for at bekræfte, lad os beregne gennemsnittet for året 1999 ved hjælp af samme procedure som før:
Da den fundne værdi ikke er mindre end 21 år, vil dette alternativ også være forkert.
Alternativ: d) gennemsnit af mødre til børn født i 2004 var større end 22 år.
8) UPE - 2014
I en sportskonkurrence bestrider fem atleter de tre øverste placeringer i længdespringkonkurrencen. Klassificeringen vil være i faldende rækkefølge af det aritmetiske gennemsnit af point opnået af dem efter tre på hinanden følgende spring i testen. I tilfælde af uafgjort er det vedtagne kriterium den stigende rækkefølge af variansværdien. Hver atletes score vises i nedenstående tabel:

Baseret på de præsenterede oplysninger blev første, anden og tredje plads i denne konkurrence besat henholdsvis af atleterne
a) A; Ç; OG
b) B; D; OG
c) OG; D; B
d) B; D; Ç
og; B; D
Lad os starte med at beregne det aritmetiske gennemsnit for hver atlet:
Da alle er bundet, beregner vi variansen:
Da klassificeringen udføres i faldende rækkefølge, vil førstepladsen være atlet A efterfulgt af atlet C og E.
Alternativ: a) A; Ç; OG
Få mere viden med indholdet:
- Standardafvigelse
- Variation og standardafvigelse
- Sandsynlighedsøvelser