
Při získávání jakéhokoli vzorku o velikosti n se vypočítá aritmetický průměr vzorku. Pravděpodobně, pokud je odebrán nový náhodný vzorek, získaný aritmetický průměr se bude lišit od aritmetického průměru prvního vzorku. Variabilita prostředků se odhaduje podle jejich standardní chyby. Standardní chyba tedy posuzuje přesnost výpočtu střední hodnoty populace.
Standardní chyba je dána vzorcem:
Kde,
sX → je standardní chyba
s → je směrodatná odchylka
n → je velikost vzorku
Poznámka: Čím lepší je přesnost výpočtu střední hodnoty populace, tím menší je standardní chyba.
Příklad 1. V populaci byla u náhodného vzorku 60 prvků získána standardní odchylka 2,64. Jaká je pravděpodobná standardní chyba?
Řešení: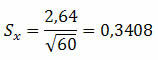
To znamená, že průměr se může lišit o 0,3408 více či méně.
Příklad 2. V populaci byla u náhodného vzorku 121 prvků získána standardní odchylka 1,32. S vědomím, že u stejného vzorku bylo získáno průměrně 6,25, určete nejpravděpodobnější hodnotu průměru dat.
Řešení: K určení nejpravděpodobnější střední hodnoty dat musíme vypočítat standardní chybu odhadu. Budeme tedy mít:

A konečně nejpravděpodobnější hodnotu průměru získaných údajů lze představovat:
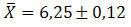
Autor: Marcelo Rigonatto
Specialista na statistiku a matematické modelování
Tým brazilské školy
Statistický - Matematika - Brazilská škola
Zdroj: Brazilská škola - https://brasilescola.uol.com.br/matematica/erro-padrao-estimativa.htm

