
korelacja oznacza podobieństwo lub związek między dwiema rzeczami, ludźmi lub pomysłami. Jest to podobieństwo lub równoważność, która istnieje między dwiema różnymi hipotezami, sytuacjami lub przedmiotami.
W dziedzinie statystyki i matematyki korelacja odnosi się do miary między dwiema lub większą liczbą powiązanych zmiennych.
Termin korelacja to rzeczownik rodzaju żeńskiego, który pochodzi z łaciny korelat.
Słowo korelacja można zastąpić takimi synonimami, jak: relacja, równoważność, powiązanie, korespondencja, analogia i powiązanie.
Współczynnik korelacji
W statystykach Współczynnik korelacji Pearsona (r), który jest również nazywany współczynnikiem korelacji produktu-pędu, mierzy związek istniejący między dwiema zmiennymi w tej samej skali metrycznej.
Funkcją współczynnika korelacji jest określenie siły związku istniejącego między zestawami znanych danych lub informacji.
Wartość współczynnika korelacji może wahać się od -1 do 1, a otrzymany wynik określa, czy korelacja jest ujemna czy dodatnia.
Aby zinterpretować współczynnik, trzeba wiedzieć, że 1 oznacza, że korelacja między zmiennymi jest doskonały pozytyw a -1 oznacza, że jest doskonały negatyw. Jeżeli współczynnik jest równy 0, oznacza to, że zmienne nie są od siebie zależne.
W statystykach jest też Współczynnik korelacji Spearmana, nazwany na cześć statystyka Charlesa Spearmana. Funkcją tego współczynnika jest pomiar intensywności związku między dwiema zmiennymi, niezależnie od tego, czy są liniowe, czy nie.
Korelacja Spearmana służy do oceny, czy nasilenie związku między dwiema analizowanymi zmiennymi można zmierzyć za pomocą funkcji monotonnej (funkcji matematycznej, która zachowuje lub odwraca relację porządku) Inicjał).
Obliczanie współczynnika korelacji Pearsona
Metoda 1) Obliczenie współczynnika korelacji Pearsona z wykorzystaniem kowariancji i odchylenia standardowego.
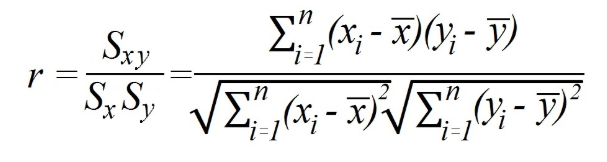
Gdzie
sXYjest kowariancją;
sx i stakreprezentują odpowiednio odchylenie standardowe zmiennych x i y.
W tym przypadku obliczenia obejmują najpierw znalezienie kowariancji między zmiennymi i odchylenia standardowego każdej z nich. Następnie podziel kowariancję, mnożąc odchylenia standardowe.
Często stwierdzenie zawiera już albo odchylenia standardowe zmiennych, albo kowariancję między nimi, po prostu stosując wzór.
Metoda 2) Obliczenie współczynnika korelacji Pearsona z danymi surowymi (brak kowariancji lub odchylenia standardowego).
W przypadku tej metody najbardziej bezpośrednia formuła wygląda następująco:
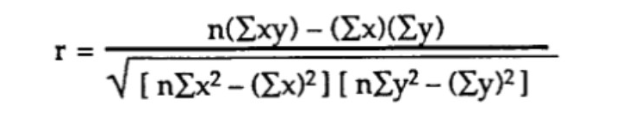
Na przykład, zakładając, że mamy dane z n=6 obserwacjami dwóch zmiennych: poziomu glukozy (y) i wieku (x), obliczenia przebiegają według następujących kroków:
Krok 1) Zbuduj tabelę z istniejących danych: i, x, y i dodaj puste kolumny dla xy, x² i y²:
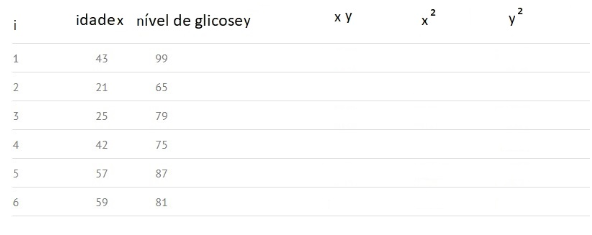
Krok 2: Pomnóż x i y, aby wypełnić kolumnę „xy”. Na przykład w linii 1 będziemy mieli: x1y1 = 43 × 99 = 4257.

Krok 3: Podnieś wartości do kwadratu w kolumnie x i zapisz wyniki w kolumnie x². Na przykład w pierwszym wierszu będziemy mieli x12 = 43 × 43 = 1849.

Krok 4: Zrób to samo, co w kroku 3, teraz używając kolumny y i zapisz kwadrat swoich wartości w kolumnie y². Na przykład w pierwszym wierszu będziemy mieli: y12 = 99 × 99 = 9801.

Krok 5: Uzyskaj sumę wszystkich numerów kolumn i umieść wynik w stopce kolumny. Na przykład suma w kolumnie Wiek X wynosi 43+21+25+42+57+59 = 247.

Krok 6: Użyj powyższego wzoru, aby uzyskać współczynnik korelacji:

Więc mamy:

Obliczanie współczynnika korelacji Spearmana
Obliczenie współczynnika korelacji Spearmana jest nieco inne. W tym celu musimy uporządkować nasze dane w poniższej tabeli:
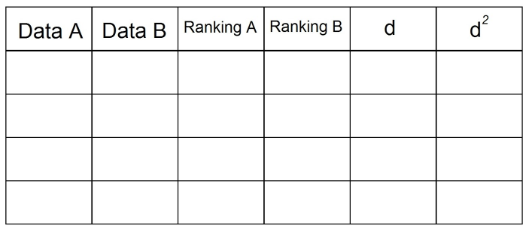
1. Mając w zestawieniu 2 pary danych, musimy wprowadzić je do tabeli. Na przykład:
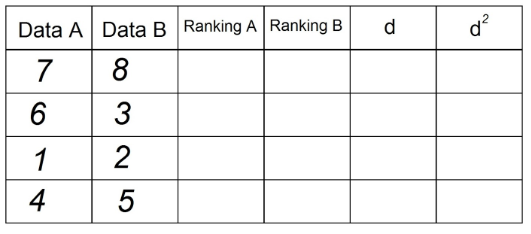
2. W kolumnie „Ranking A” posortujemy obserwacje, które znajdują się w „Dacie A” rosnąco, będąc „1” najniższa wartość w kolumnie, a n (łączna liczba obserwacji) najwyższa wartość w kolumnie „Data” THE". W naszym przykładzie jest to:
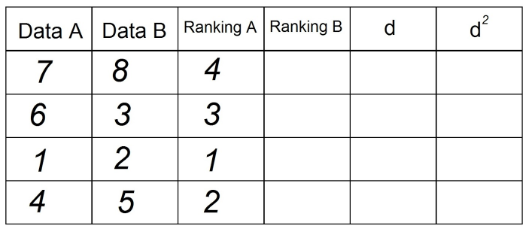
3. To samo robimy, aby uzyskać kolumnę „Ranking B”, wykorzystując teraz obserwacje w kolumnie „Dane B”:
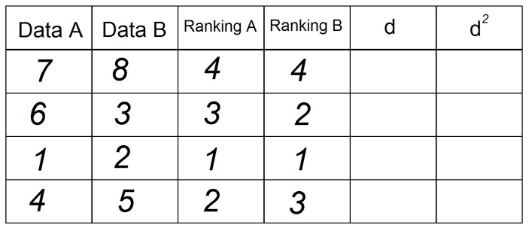
4. W kolumnie „d” umieszczamy różnicę między dwoma Rankingami (A - B). Tutaj sygnał nie ma znaczenia.

5. Kwadratuj każdą z wartości w kolumnie „d” i zapisz w kolumnie d²:
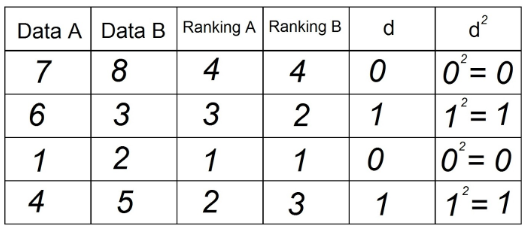
6. Zsumuj wszystkie dane z kolumny „d²”. Ta wartość to Σd². W naszym przykładzie Σd² = 0+1+0+1 = 2
7. Teraz korzystamy ze wzoru Spearmana:
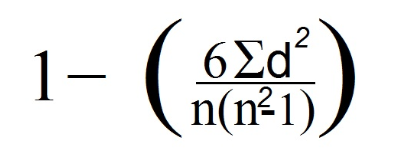
W naszym przypadku n jest równe 4, ponieważ patrzymy na liczbę linii danych (co odpowiada liczbie obserwacji).
8. Ostatecznie zastąpiliśmy dane w poprzedniej formule:
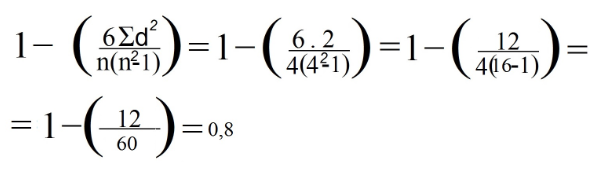
regresja liniowa
Regresja liniowa to formuła używana do oszacowania możliwej wartości zmiennej (y), gdy znane są wartości innych zmiennych (x). Wartość „x” jest zmienną niezależną lub objaśniającą, a „y” jest zmienną zależną lub odpowiedzią.
Regresja liniowa służy do sprawdzenia, jak wartość „y” może się zmieniać w funkcji zmiennej „x”. Linia zawierająca wartości kontroli wariancji nazywana jest linią regresji liniowej.
Jeśli zmienna objaśniająca „x” ma pojedynczą wartość, regresja zostanie nazwana prosta regresja liniowa.
