
크기가 n 인 표본을 얻을 때 표본 산술 평균이 계산됩니다. 아마도 새로운 무작위 표본이 취해지면 얻은 산술 평균은 첫 번째 표본의 산술 평균과 다를 것입니다. 평균의 변동성은 표준 오차로 추정됩니다. 따라서 표준 오차는 모집단 평균 계산의 정확성을 평가합니다.
표준 오류는 다음 공식으로 제공됩니다.
어디,
에스엑스 → 표준 오류입니다.
s → 표준 편차
n → 샘플 크기
참고: 모집단 평균 계산의 정밀도가 높을수록 표준 오차는 작아집니다.
예 1. 모집단에서 60 개 요소의 무작위 표본으로 2.64의 표준 편차를 얻었습니다. 가능한 표준 오류는 무엇입니까?
해결책: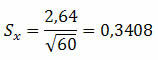
이것은 평균이 0.3408 다소 다를 수 있음을 나타냅니다.
예 2. 모집단에서 121 개 요소의 무작위 표본으로 1.32의 표준 편차를 얻었습니다. 이 동일한 샘플에 대해 평균 6.25가 얻어 졌다는 것을 알고 데이터의 평균에 대해 가장 가능성이 높은 값을 결정합니다.
솔루션: 데이터의 가장 가능성있는 평균값을 결정하려면 추정값의 표준 오차를 계산해야합니다. 따라서 우리는 다음을 갖게 될 것입니다.
마지막으로, 얻은 데이터의 평균에 대한 가능성이 가장 높은 값은 다음과 같이 나타낼 수 있습니다.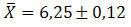
Marcelo Rigonatto 작성
통계 및 수학적 모델링 전문가
브라질 학교 팀
통계량 - 수학 - 브라질 학교
출처: 브라질 학교- https://brasilescola.uol.com.br/matematica/erro-padrao-estimativa.htm
