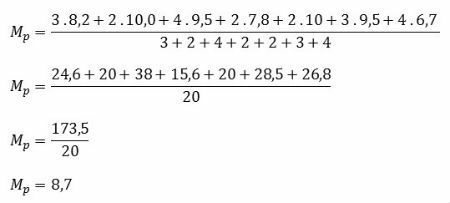Bármely n méretű minta megszerzésekor kiszámítják a minta számtani átlagát. Valószínűleg, ha új véletlenszerű mintát veszünk, a kapott számtani átlag eltér az első mintától. Az átlagok változékonyságát standard hibájukkal becsüljük meg. Így a standard hiba értékeli a sokaság átlaga számításának pontosságát.
A standard hibát a képlet adja meg:
Hol,
sx → a szokásos hiba
s → a szórás
n → a minta mérete
Megjegyzés: Minél jobb a pontosság a sokaság átlagának kiszámításakor, annál kisebb a standard hiba.
1. példa Egy populációban 2,64-es szórást kaptunk 60 elemből álló véletlenszerű mintával. Mi a valószínű standard hiba?
Megoldás: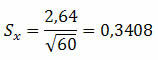
Ez azt jelzi, hogy az átlag 0,3408 többé-kevésbé változhat.
2. példa Egy populációban 121 elemből álló véletlenszerű mintával 1,32 szórást kaptunk. Annak tudatában, hogy ugyanarra a mintára átlagosan 6,25-öt kapott, határozza meg az adatok átlagának legvalószínűbb értékét.
Megoldás: Az adatok legvalószínűbb átlagértékének meghatározásához ki kell számolnunk a becslés standard hibáját. Így lesz:

Végül a kapott adatok átlagának legvalószínűbb értéke a következőképpen ábrázolható:
Ne álljon meg most... A reklám után még több van;)
Írta: Marcelo Rigonatto
Statisztikai és matematikai modellezési szakember
Brazil iskolai csapat
Statisztikai - Math - Brazil iskola
Hivatkozni szeretne erre a szövegre egy iskolai vagy tudományos munkában? Néz:
RIGONATTO, Marcelo. "A becslés standard hibája"; Brazil iskola. Elérhető: https://brasilescola.uol.com.br/matematica/erro-padrao-estimativa.htm. Hozzáférés: 2021. június 27.