
आकार n का कोई भी नमूना प्राप्त करते समय, नमूना अंकगणितीय माध्य की गणना की जाती है। संभवतः, यदि एक नया यादृच्छिक नमूना लिया जाता है, तो प्राप्त अंकगणितीय माध्य पहले नमूने से भिन्न होगा। साधनों की परिवर्तनशीलता का अनुमान उनकी मानक त्रुटि से लगाया जाता है। इस प्रकार, मानक त्रुटि जनसंख्या माध्य की गणना की सटीकता का मूल्यांकन करती है।
मानक त्रुटि सूत्र द्वारा दी गई है:
कहा पे,
रोंएक्स → मानक त्रुटि है
s → मानक विचलन है
n → नमूना आकार है
नोट: जनसंख्या माध्य की गणना में सटीकता जितनी बेहतर होगी, मानक त्रुटि उतनी ही कम होगी।
उदाहरण 1। एक जनसंख्या में, 60 तत्वों के यादृच्छिक नमूने के साथ 2.64 का मानक विचलन प्राप्त किया गया था। संभावित मानक त्रुटि क्या है?
समाधान: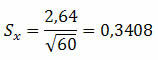
यह इंगित करता है कि औसत 0.3408 अधिक या कम भिन्न हो सकता है।
उदाहरण २। एक जनसंख्या में, 121 तत्वों के यादृच्छिक नमूने के साथ 1.32 का मानक विचलन प्राप्त किया गया था। यह जानते हुए कि इसी नमूने के लिए औसतन 6.25 प्राप्त किया गया था, डेटा के औसत के लिए सबसे संभावित मूल्य निर्धारित करें।
समाधान: डेटा के सबसे संभावित औसत मूल्य को निर्धारित करने के लिए हमें अनुमान की मानक त्रुटि की गणना करनी चाहिए। इस प्रकार, हमारे पास होगा:

अंत में, प्राप्त आंकड़ों के औसत के लिए सबसे संभावित मूल्य द्वारा दर्शाया जा सकता है:
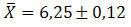
मार्सेलो रिगोनाट्टो द्वारा
सांख्यिकी और गणितीय मॉडलिंग में विशेषज्ञ
ब्राजील स्कूल टीम
सांख्यिकीय - गणित - ब्राजील स्कूल
स्रोत: ब्राजील स्कूल - https://brasilescola.uol.com.br/matematica/erro-padrao-estimativa.htm