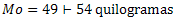LES statistique est le domaine des mathématiques qui lister des faits et des chiffres dans lequel il existe un ensemble de méthodes qui nous permettent de collecter des données et de les analyser, permettant ainsi d'en effectuer une certaine interprétation. La statistique est divisée en deux parties: descriptif et inférentielle. Les statistiques descriptives se caractérisent par l'organisation, l'analyse et la présentation des données, tandis que les statistiques inférentielles ont comme caractéristique l'étude d'un échantillon d'une population donnée et, sur cette base, la réalisation d'analyses et la présentation de Dé.
A lire aussi: Quelle est la marge d'erreur d'un sondage ?
Principes de la statistique
Ensuite, nous verrons les principaux concepts et principes de la statistique. A partir d'eux, il sera possible de définir des concepts plus sophistiqués.
population ou univers statistique
La population ou l'univers statistique est le ensemble formé par tous les éléments qui participent à un sujet de recherche particulier.
Exemples d'univers statistiques
a) Dans une ville, tous les habitants appartiennent à l'univers statistique.
b) Sur un dé à six faces, la population est donnée par le nombre de faces.
{1, 2, 3, 4, 5, 6}
donnée statistique
Les données statistiques sont un élément qui appartient à l'ensemble de la population, évidemment ces données doivent être liées au sujet de recherche.
Population |
donnée statistique |
dés à six faces |
4 |
Champions brésiliens de VTT |
Henrique Avancini |
Goûter
Nous appelons l'échantillon le sous-ensemble formé à partir d'un univers statistique. Un échantillon est utilisé lorsque la population est très grande ou infinie. Dans les cas où la collecte de toutes les informations de l'univers statistique est impossible pour des raisons financières ou logistiques, il est également nécessaire d'utiliser des échantillons.
Le choix d'un échantillon est extrêmement important pour une recherche, et il doit représenter de manière fiable la population. Un exemple classique d'utilisation d'échantillons dans une enquête est la réalisation de recensement démographique de notre pays.
Variable
En statistique, la variable est l'objet d'étude, c'est-à-dire le sujet que la recherche a l'intention d'étudier. Par exemple, lorsqu'on étudie les caractéristiques d'une ville, le nombre d'habitants peut être une variable, ainsi que le volume de pluie sur une période donnée ou encore le nombre de bus pour le transport Publique. Notons que la notion de variable en statistique dépend du contexte de recherche.
L'organisation des données dans les statistiques a lieu dans phases, comme dans tout processus d'organisation. Dans un premier temps, le sujet à rechercher est choisi, puis la méthode de collecte des données de recherche est réfléchie et la troisième étape consiste à effectuer la collecte. Après la fin de cette dernière étape, l'analyse de ce qui a été collecté est effectuée, et ainsi, sur la base de l'interprétation, des résultats sont recherchés. Nous allons maintenant voir quelques concepts importants et nécessaires pour l'organisation des données.
Ne vous arrêtez pas maintenant... Y'a plus après la pub ;)
rôle
Dans les cas où les données peuvent être représentées par des nombres, c'est-à-dire lorsque la variable est quantitative, la liste des organisation de ces données. Une liste peut être ascendante ou descendante. Si une variable n'est pas quantitative, c'est-à-dire si elle est qualitative, il n'est pas possible d'utiliser la liste, par exemple, si les données sont des sentiments sur un produit particulier.
Exemple
Dans une salle de classe, les tailles des élèves en mètres ont été recueillies. Ils sont: 1,70; 1,60; 1,65; 1,78; 1,71; 1,73; 1,72; 1,64.
La liste pouvant être organisée de manière ascendante ou descendante, il s'ensuit que :
rôle: (1,60; 1,64; 1,65; 1,70; 1,71; 1,72; 1,73; 1,78}
A noter qu'avec le rouleau déjà assemblé, il est possible de retrouver des données plus facilement.
Tableau de répartition des fréquences
Dans les cas où il y a de nombreux éléments dans la liste et de nombreuses répétitions de données, la liste devient obsolète, car l'organisation de ces données est impraticable. Dans ces cas, les tableaux et les distribution de fréquence ils constituent un excellent outil d'organisation.
Dans le tableau de répartition de fréquence absolue, il faut mettre la fréquence à laquelle chaque donnée apparaît, c'est-à-dire le nombre de fois où elle apparaît.
Construisons la table de distribution pour fréquence absolue l'âge, en années, des élèves d'une classe donnée.
Distribution de fréquence absolue | |
Âge |
Fréquence (F) |
8 |
2 |
9 |
12 |
10 |
12 |
11 |
14 |
12 |
1 |
Total (FT) |
41 |
À partir du tableau, nous pouvons obtenir les informations suivantes: dans la classe, nous avons 2 élèves âgés de 8, 12 ans Les élèves de 9 ans, et 12 autres élèves de 10 ans, et ainsi de suite, pour atteindre un total de 41 étudiants. Dans le tableau de répartition de fréquences accumulées, il faut ajouter la fréquence de la ligne précédente (dans le tableau de distribution de fréquence absolue).
Construisons le tableau de distribution des fréquences cumulées pour les âges de la même classe que dans l'exemple précédent, voir :
Distribution de fréquence cumulée | |
Âge |
Fréquence (F) |
8 |
2 |
9 |
14 |
10 |
26 |
11 |
40 |
12 |
41 |
Total (FT) |
41 |
Dans le tableau de répartition des fréquences relatives, le pourcentage dans lequel chaque donnée apparaît est utilisé. Encore une fois, nous ferons les calculs sur la base du tableau de distribution de fréquence absolue. On sait que 41 correspond à 100 % des élèves de la classe, donc pour déterminer le pourcentage de chaque âge, nous divisons simplement la fréquence de l'âge par 41 et multiplions le résultat par 100, afin que nous puissions l'écrire en pourcentage.
2: 41 = 0,048 · 100 → 4,8%
12: 41 = 0,292 · 100 → 29,2%
12: 41 = 0,292 · 100 → 29,2%
14: 41 = 0,341 · 100 → 34,1%
1: 41 = 0,024 · 100 → 2,4%
Distribution de fréquence relative | |
Âge |
Fréquence (F) |
8 |
4,8% |
9 |
29,2% |
10 |
29,2% |
11 |
34,1% |
12 |
2,4% |
Total (FT) |
100% |
A lire aussi :Application de etstatistiques: Fla fréquence leabsolue et Ffréquence relative
Des classes
Dans les cas où la variable est continue, c'est-à-dire lorsqu'elle a plusieurs valeurs, il est nécessaire de les regrouper en intervalles réels. En statistique, ces intervalles sont appelés classes..
Pour construire le tableau de répartition des fréquences dans les classes, il faut mettre les intervalles dans la colonne de gauche, avec leur titre propre, et dans la colonne de droite, il faut mettre la fréquence absolue de chacun des intervalles, c'est-à-dire combien d'éléments appartiennent à chacun leur.
Exemple
Taille des élèves en 3e année de lycée dans une école.
Répartition des fréquences dans les classes | |
hauteur (mètres) |
Fréquence absolue (F) |
[1,40; 1,50[ |
1 |
[1,50; 1,60[ |
4 |
[1,60; 1,70[ |
8 |
[1,70; 1,80[ |
2 |
[1,80; 1,90[ |
1 |
Total (FT) |
16 |
En analysant le tableau de répartition des fréquences dans les classes, nous pouvons constater que, en classe de troisième année, nous avons 1 élève qui a une hauteur comprise entre 1,40 m et 1,50 m, tout comme nous avons 4 élèves avec une taille comprise entre 1,50 et 1,60 m, et ainsi successivement. On peut également observer que les élèves ont des hauteurs comprises entre 1,40 m et 1,90 m, la différence entre ces mesures, c'est-à-dire entre la plus haute et la plus basse hauteur de l'échantillon, est appelée amplitude.
La différence entre les bornes supérieure et inférieure d'une classe est appelée la largeur de classe, ainsi, la seconde, qui compte 4 élèves avec des hauteurs comprises entre 1,50 mètre (inclus) et 1,60 mètre (non inclus), a une portée de :
1,60 – 1,50
0,10 mètre
Voir aussi: Mesures de dispersion: amplitude et déviation
mesures de position
Les mesures de position sont utilisées dans les cas où il est possible de construire un rouleau numérique avec les données ou une table de fréquence. Ces mesures indiquent la position des éléments par rapport au roster. Les trois principales mesures de position sont :
Moyenne
Considérez la liste avec les éléments (un1, une2, une3, une4, …, Lenon), la moyenne arithmétique de ces n éléments est donnée par :
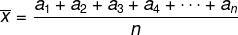
Exemple
Dans un groupe de danse, les âges des membres ont été collectés et représentés dans la liste suivante :
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Déterminons l'âge moyen des membres de ce groupe de danse.
D'après la formule, il faut additionner tous les éléments et diviser ce résultat par le nombre d'éléments de la liste, comme ceci :
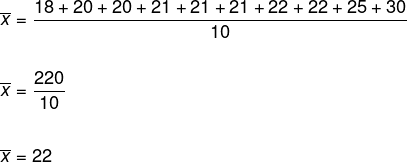
Par conséquent, l'âge moyen des membres est de 22 ans.
Pour en savoir plus sur cette mesure de position, lisez notre texte: MéMatin.
médian
La médiane est donnée par l'élément central d'une liste qui a un nombre impair d'éléments. Si la liste a un nombre pair d'éléments, il faut considérer les deux éléments centraux et calculer la moyenne arithmétique entre eux.
Exemple
Considérez la liste suivante.
(2, 2, 3, 3,4, 5, 6, 7, 9)
Notez que l'élément 4 divise le rôle en deux parties égales, c'est donc l'élément central.
Exemple
Calculer l'âge médian du groupe de danse.
N'oubliez pas que la liste des âges pour ce groupe de danse est donnée par :
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
Notez que le nombre d'éléments de cette liste est égal à 10, il n'est donc pas possible de diviser la liste en deux parties égales. Il faut donc prendre deux éléments centraux et effectuer la moyenne arithmétique de ces valeurs.
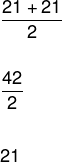
Voir plus de détails sur cette mesure de position dans notre texte: Median.
Mode
Nous appellerons mode l'élément du rôle qui a la fréquence la plus élevée, c'est-à-dire l'élément qui y apparaît le plus.
Exemple
Déterminons la mode de la liste d'âge du groupe de danse.
(18, 20, 20, 21, 21, 21, 22, 22, 25, 30)
L'élément qui apparaît le plus est 21, donc le mode est égal à 21.
Mesures de dispersion
Les mesures de dispersion sont utilisé dans les cas où la moyenne n'est plus suffisante. Par exemple, imaginez que deux voitures ont parcouru en moyenne 40 000 kilomètres. Ce n'est qu'en connaissant les moyennes que nous pouvons dire que les deux voitures ont parcouru des kilomètres déterminables chacune, n'est-ce pas ?
Cependant, imaginez que l'une des voitures a parcouru 79 000 kilomètres et que l'autre 1 000 kilomètres, notez que seulement avec des informations sur la moyenne, il n'est pas possible de faire des déclarations avec précision.
À mesures de dispersion nous dira à quelle distance les éléments d'une liste numérique sont de la moyenne arithmétique. Nous avons deux mesures importantes de la dispersion :
Écart (σ2)
Appelons la moyenne arithmétique des carrés de la différence entre chaque élément du rouleau et la moyenne arithmétique de ce rouleau comme la variance. La variance est représentée par: σ2.
Considérez la liste (x1, X2, X3, …, Xnon) et qu'il a une moyenne arithmétiqueX. La variance est donnée par :
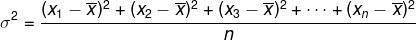
Écart-type (σ)
L'écart type est donné par la racine de la variance, il nous indique à quel point un élément est dispersé par rapport à la moyenne. L'écart type est noté .
Exemple
Déterminez l'écart type de l'ensemble de données (4, 7, 10). A noter que, pour cela, il faut d'abord déterminer la variance, et que, pour cela, il faut d'abord calculer la moyenne de ces données.
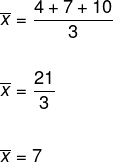
En remplaçant ces données dans la formule de la variance, nous avons :
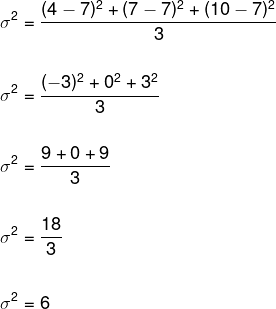
Pour déterminer l'écart type, nous devons extraire la racine de la variance.
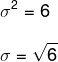
Lire la suite: Mesures de dispersion: variance et écart type
A quoi servent les statistiques ?
Nous avons vu que la statistique est liée à Problèmes de comptage ou d'organisation des données. De plus, il a un rôle important dans le développement d'outils qui permettent le processus d'organisation des données, tels que les tableaux. Les statistiques sont également présentes dans divers domaines scientifiques, basé sur la collecte et le traitement des données, il est possible de travailler avec des modèles mathématiques qui permettent un développement ultérieur dans le domaine étudié. Quelques domaines dans lesquels les statistiques sont fondamentales: économie, météorologie, marketing, sports, sociologie et géosciences.
En météorologie, par exemple, les données sont collectées dans une certaine période, après avoir été organisées, elles sont traitées, et ainsi, avec sur la base d'eux, un modèle mathématique est construit qui nous permet d'affirmer sur le climat des jours précédents avec un plus grand degré de fiabilité. La statistique est une branche de la science qui nous permet de faire des déclarations avec un certain degré de fiabilité, mais jamais de certitude à 100 %.
Divisions statistiques
Les statistiques sont divisées en deux parties, descriptive et inférentielle. La première est liée au comptage des éléments impliqués dans la recherche, ces éléments sont comptés un par un. À Statistiques descriptives, nos principaux outils sont les mesures de position, telles que la moyenne, la médiane et le mode, ainsi que mesures de dispersion telles que la variance et l'écart type, nous avons également des tableaux de fréquences et graphique.
Toujours en statistique descriptive, nous avons une méthodologie très bien définie pour une présentation des données avec un degré de fiabilité considérable qui passe par l'organisation et la collecte, la synthèse, l'interprétation et la représentation et, enfin, l'analyse des données. Un exemple classique de l'utilisation des statistiques descriptives se trouve dans le recensement de la population (tous les 10 ans) par l'Institut brésilien de géographie et de statistique (IBGE).
LES statistiques déductives, à son tour, il se caractérise non pas par la collecte de données à partir des éléments d'une population un par un, mais par la réalisation de analyse d'un échantillon de cette population, en tirant des conclusions à son sujet. En statistique inférentielle, il faut être prudent dans le choix de l'échantillon, car il doit très bien représenter la population. Certains premiers résultats, tels que la moyenne, dans les statistiques inférentielles appelées espoirs, sont déduits à partir de la connaissance des statistiques descriptives.
Les statistiques déductives sont utilisées, par exemple, dans les sondages électoraux. Un échantillon de la population est choisi, d'une manière qui la représente, et ainsi la recherche est effectuée. Lorsqu'on choisit un échantillon qui ne représente pas très bien cette population, on dit que la recherche est biaisé et donc peu fiable.
exercices résolus
question 1 – (U. F. Juiz de Fora – MG) Un professeur de physique a appliqué un test, valant 100 points, à ses 22 élèves et a obtenu, en conséquence, la répartition des notes, vue dans le tableau suivant :
40 |
20 |
10 |
20 |
70 |
60 |
90 |
80 |
30 |
50 |
50 |
70 |
50 |
20 |
50 |
50 |
10 |
40 |
30 |
20 |
60 |
60 |
– |
– |
Effectuer les traitements de données suivants :
a) Écris la liste de ces notes.
b) Détermine la fréquence relative de la note la plus haute.
Résolution
a) Pour faire la liste de ces notes, il faut les écrire de manière ascendante ou descendante. Nous devons donc :
10, 10, 20, 20, 20, 20, 30, 30, 40, 40, 50, 50, 50, 50, 50, 60, 60, 60, 80, 90
b) En regardant le rouleau, on voit que la note la plus haute était égale à 90 et que sa fréquence absolue est égale à 1, car elle n'apparaît qu'une seule fois. Pour déterminer la fréquence relative, nous devons diviser la fréquence absolue de cette note par la fréquence totale, dans ce cas égale à 22. Ainsi:
fréquence relative
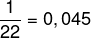
Pour passer ce nombre en pourcentage, il faut le multiplier par 100.
0,045 · 100
4,5%
Question 2 – (Enem) Après avoir lancé un dé en forme de cube avec des faces numérotées de 1 à 6, 10 fois consécutives, et noter le nombre obtenu à chaque coup, le tableau suivant de répartition des fréquences.
Nombre obtenu |
La fréquence |
1 |
4 |
2 |
1 |
4 |
2 |
5 |
2 |
6 |
1 |
La moyenne, la médiane et le mode de cette distribution de fréquence sont respectivement :
a) 3, 2 et 1
b) 3, 3 et 1
c) 3, 4 et 2
d) 5, 4 et 2
e) 6, 2 et 4
Résolution
Variante B.
Pour déterminer la moyenne, notez qu'il y a répétition des nombres obtenus, nous utiliserons donc la moyenne arithmétique pondérée.
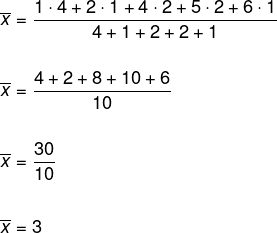
Pour déterminer la médiane, nous devons organiser la liste de manière ascendante ou descendante. N'oubliez pas que la fréquence est le nombre de fois où le visage apparaît.
1, 1, 1, 1, 2, 4, 4, 5, 5, 6
Comme le nombre d'éléments du roster est pair, il faut calculer la moyenne arithmétique des éléments centraux qui divisent le roster en deux pour déterminer la médiane, comme ceci :
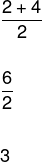
Le mode est donné par l'élément qui apparaît le plus, c'est-à-dire qu'il a la fréquence la plus élevée, on a donc que le mode est égal à 1.
Ainsi, la moyenne, la médiane et le mode sont, respectivement, égaux à :
3, 3 et 1
par Robson Luiz
Professeur de mathématiques
Dans un groupe de personnes, les âges sont: 10, 12, 15 et 17 ans. Si un jeune de 16 ans rejoint le groupe, qu'arrive-t-il à l'âge moyen du groupe?
Calculez le salaire moyen de cette entreprise.