Korrelation bedeutet Ähnlichkeit oder Beziehung zwischen zwei Dingen, Menschen oder Ideen. Es ist eine Ähnlichkeit oder Äquivalenz, die zwischen zwei verschiedenen Hypothesen, Situationen oder Objekten besteht.
Im Bereich Statistik und Mathematik bezieht sich Korrelation auf ein Maß zwischen zwei oder mehr Variablen, die miteinander in Beziehung stehen.
Der Begriff Korrelation ist ein weibliches Substantiv, das aus dem Lateinischen stammt zueinander in Beziehung stehen.
Das Wort Korrelation kann durch Synonyme ersetzt werden wie: Relation, Äquivalenz, Nexus, Korrespondenz, Analogie und Verbindung.
Korrelationskoeffizient
In der Statistik Korrelationskoeffizient nach Pearson (r), auch Produkt-Impuls-Korrelationskoeffizient genannt, misst die Beziehung, die zwischen zwei Variablen innerhalb derselben metrischen Skala besteht.
Die Funktion des Korrelationskoeffizienten besteht darin, die Stärke der Beziehung zu bestimmen, die zwischen Sätzen bekannter Daten oder Informationen besteht.
Der Wert des Korrelationskoeffizienten kann zwischen -1 und 1 variieren und das erhaltene Ergebnis bestimmt, ob die Korrelation negativ oder positiv ist.
Um den Koeffizienten zu interpretieren, muss man wissen, dass 1 bedeutet, dass die Korrelation zwischen den Variablen perfekt positiv und -1 bedeutet es ist perfekt negativ. Wenn der Koeffizient gleich 0 ist, bedeutet dies, dass die Variablen nicht voneinander abhängen.
In der Statistik gibt es auch die Korrelationskoeffizient nach Spearman, benannt nach dem Statistiker Charles Spearman. Die Funktion dieses Koeffizienten besteht darin, die Intensität der Beziehung zwischen zwei Variablen zu messen, unabhängig davon, ob sie linear sind oder nicht.
Die Spearman-Korrelation dient dazu, zu beurteilen, ob die Intensität der Beziehung zwischen den beiden analysierten Variablen kann durch eine monotone Funktion gemessen werden (mathematische Funktion, die die Ordnungsbeziehung beibehält oder invertiert) Initiale).
Berechnung des Korrelationskoeffizienten nach Pearson
Methode 1) Berechnung des Korrelationskoeffizienten nach Pearson unter Verwendung von Kovarianz und Standardabweichung.
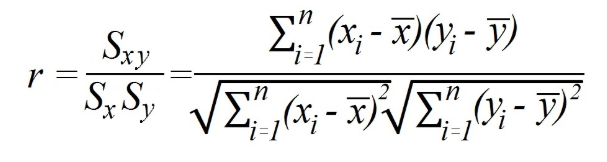
Wo
soXYist die Kovarianz;
sox und sojarepräsentieren die Standardabweichung der x- und y-Variablen.
In diesem Fall umfasst die Berechnung zunächst die Ermittlung der Kovarianz zwischen den Variablen und der Standardabweichung jeder von ihnen. Dann dividiere die Kovarianz durch Multiplikation der Standardabweichungen.
Oft liefert die Aussage bereits durch Anwendung der Formel entweder die Standardabweichungen der Variablen oder die Kovarianz zwischen ihnen.
Methode 2) Berechnung des Korrelationskoeffizienten nach Pearson mit Rohdaten (keine Kovarianz oder Standardabweichung).
Bei dieser Methode lautet die direkteste Formel wie folgt:
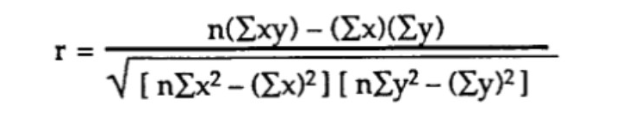
Angenommen, wir haben beispielsweise Daten mit n=6 Beobachtungen für zwei Variablen: Glukosespiegel (y) und Alter (x), dann folgt die Berechnung diesen Schritten:
Schritt 1) Erstellen Sie die Tabelle mit vorhandenen Daten: i, x, y, und fügen Sie leere Spalten für xy, x² und y² hinzu:
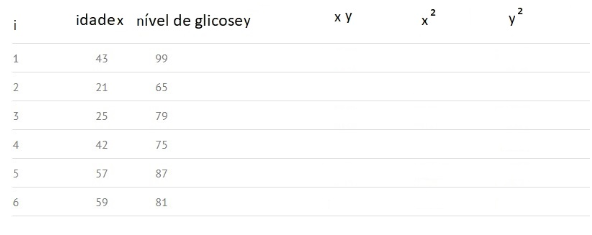
Schritt 2: Multiplizieren Sie x und y, um die Spalte „xy“ zu füllen. In Zeile 1 haben wir beispielsweise: x1y1 = 43 × 99 = 4257.

Schritt 3: Quadrieren Sie die Werte in Spalte x und notieren Sie die Ergebnisse in Spalte x². In der ersten Zeile haben wir zum Beispiel x12 = 43 × 43 = 1849.

Schritt 4: Machen Sie dasselbe wie in Schritt 3, verwenden Sie nun Spalte y und notieren Sie das Quadrat Ihrer Werte in Spalte y². In der ersten Zeile haben wir zum Beispiel: y12 = 99 × 99 = 9801.

Schritt 5: Ermitteln Sie die Summe aller Spaltennummern und platzieren Sie das Ergebnis in der Spaltenfußzeile. Die Summe der Spalte Alter X beträgt beispielsweise 43+21+25+42+57+59 = 247.

Schritt 6: Verwenden Sie die obige Formel, um den Korrelationskoeffizienten zu erhalten:

Also haben wir:

Berechnung des Korrelationskoeffizienten nach Spearman
Die Berechnung des Korrelationskoeffizienten nach Spearman ist etwas anders. Dazu müssen wir unsere Daten in der folgenden Tabelle organisieren:
1. Da wir in der Anweisung 2 Datenpaare haben, müssen wir sie in die Tabelle einfügen. Beispielsweise:
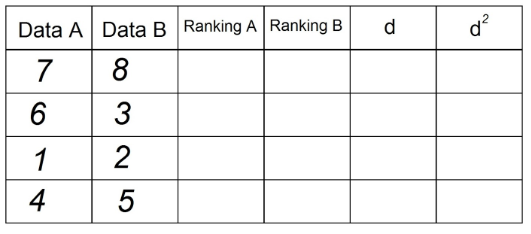
2. In der Spalte "Ranking A" sortieren wir die Beobachtungen, die sich im "Datum A" befinden, aufsteigend „1“ der niedrigste Wert in der Spalte und n (Gesamtzahl der Beobachtungen) der höchste Wert in der Spalte „Datum“ DAS". In unserem Beispiel ist es:
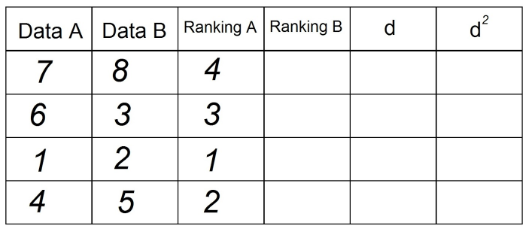
3. Wir machen dasselbe, um die Spalte „Ranking B“ zu erhalten, wobei wir nun die Beobachtungen in der Spalte „Data B“ verwenden:
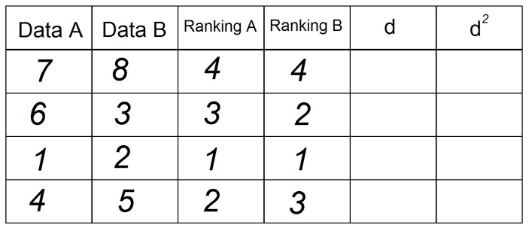
4. In Spalte „d“ tragen wir die Differenz zwischen den beiden Rankings (A - B) ein. Hier spielt das Signal keine Rolle.

5. Quadrieren Sie jeden der Werte in Spalte "d" und notieren Sie in Spalte d²:
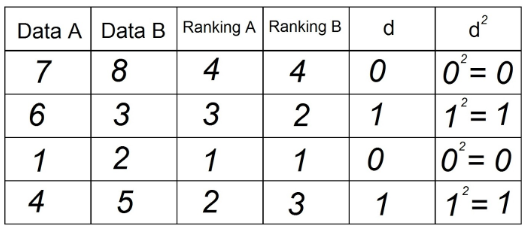
6. Summiere alle Daten aus Spalte "d²". Dieser Wert ist Σd². In unserem Beispiel Σd² = 0+1+0+1 = 2
7. Jetzt verwenden wir die Spearman-Formel:
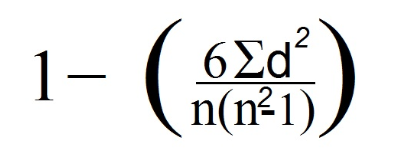
In unserem Fall ist n gleich 4, wenn wir uns die Anzahl der Datenzeilen (die der Anzahl der Beobachtungen entspricht) ansehen.
8. Schließlich haben wir die Daten in der vorherigen Formel ersetzt:
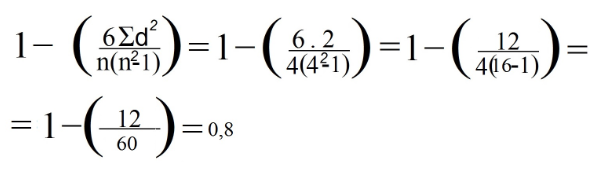
lineare Regression
Die lineare Regression ist eine Formel, die verwendet wird, um den möglichen Wert einer Variablen (y) zu schätzen, wenn die Werte anderer Variablen (x) bekannt sind. Der Wert von "x" ist die unabhängige oder erklärende Variable und "y" ist die abhängige Variable oder Antwort.
Lineare Regression wird verwendet, um zu sehen, wie der Wert von "y" als Funktion der Variablen "x" variieren kann. Die Linie, die die Varianzprüfwerte enthält, wird als lineare Regressionsgerade bezeichnet.
Wenn die erklärende Variable "x" einen einzelnen Wert hat, wird die Regression aufgerufen einfache lineare Regression.