
Bij het verkrijgen van een steekproef van grootte n, wordt het rekenkundig gemiddelde van de steekproef berekend. Als een nieuwe willekeurige steekproef wordt genomen, zal het verkregen rekenkundig gemiddelde waarschijnlijk verschillen van dat van de eerste steekproef. De variabiliteit van gemiddelden wordt geschat op basis van hun standaardfout. De standaardfout evalueert dus de nauwkeurigheid van de berekening van het populatiegemiddelde.
De standaardfout wordt gegeven door de formule:
Waar,
zoX → is de standaardfout
s → is de standaarddeviatie
n → is de steekproefomvang
Opmerking: hoe nauwkeuriger de berekening van het populatiegemiddelde, hoe kleiner de standaardfout.
Voorbeeld 1. In een populatie werd een standaarddeviatie van 2,64 verkregen met een willekeurige steekproef van 60 elementen. Wat is de waarschijnlijke standaardfout?
Oplossing: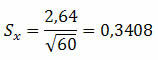
Dit geeft aan dat het gemiddelde 0,3408 meer of minder kan variëren.
Voorbeeld 2. In een populatie werd een standaarddeviatie van 1,32 verkregen met een willekeurige steekproef van 121 elementen. Wetende dat een gemiddelde van 6,25 werd verkregen voor dezelfde steekproef, bepaal dan de meest waarschijnlijke waarde voor het gemiddelde van de gegevens.
Oplossing: om de meest waarschijnlijke gemiddelde waarde van de gegevens te bepalen, moeten we de standaardfout van de schatting berekenen. Zo zullen we hebben:

Ten slotte kan de meest waarschijnlijke waarde voor het gemiddelde van de verkregen gegevens worden weergegeven door:
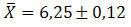
Door Marcelo Rigonatto
Specialist in statistiek en wiskundige modellering
Brazilië School Team
statistiek - Wiskunde - Brazilië School
Bron: Brazilië School - https://brasilescola.uol.com.br/matematica/erro-padrao-estimativa.htm