
상관은 유사성 또는 두 가지, 사람 또는 아이디어 간의 관계. 두 가지 다른 가설, 상황 또는 대상 사이에 존재하는 유사성 또는 동등성입니다.
통계 및 수학 분야에서 상관은 관련된 둘 이상의 변수 간의 측정 값을 나타냅니다.
용어 상관 관계는 라틴어에서 유래 한 여성 명사입니다. 상관.
상관이라는 단어는 관계, 동등성, 연관성, 대응 성, 유추 및 연결과 같은 동의어로 대체 될 수 있습니다.
상관 계수
통계에서 피어슨의 상관 계수 (r)은 제품-운동량 상관 계수라고도하며 동일한 척도 내에서 두 변수 사이에 존재하는 관계를 측정합니다.
상관 계수의 기능은 알려진 데이터 또는 정보 세트 사이에 존재하는 관계의 강도를 판별하는 것입니다.
상관 계수의 값은 -1과 1 사이에서 달라질 수 있으며 얻은 결과는 상관 관계가 음수인지 양수인지를 정의합니다.
계수를 해석하려면 1은 변수 간의 상관 관계가 다음과 같음을 의미한다는 것을 알아야합니다. 완벽한 긍정 -1은 완벽한 부정. 계수가 0이면 변수가 서로 의존하지 않음을 의미합니다.
통계에는 또한 Spearman 상관 계수, 통계 학자 Charles Spearman의 이름을 따서 명명되었습니다. 이 계수의 기능은 두 변수가 선형이든 아니든 관계의 강도를 측정하는 것입니다.
Spearman 상관 관계는 분석 된 두 변수 간의 관계 강도를 평가하는 데 사용됩니다. 단조로운 함수 (순서 관계를 보존하거나 반전하는 수학 함수)로 측정 할 수 있습니다. 머리 글자).
Pearson의 상관 계수 계산
방법 1) 공분산과 표준 편차를 이용한 Pearson 상관 계수 계산.
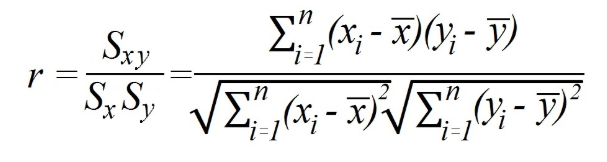
어디
에스XY공분산입니다.
에스엑스 과 에스와이x 및 y 변수의 표준 편차를 각각 나타냅니다.
이 경우 계산에는 먼저 변수 간의 공분산과 각 변수의 표준 편차를 찾는 것이 포함됩니다. 그런 다음 표준 편차를 곱하여 공분산을 나눕니다.
종종 문은 수식을 적용하여 변수의 표준 편차 또는 변수 간의 공분산을 이미 제공합니다.
방법 2) 원시 데이터와 Pearson의 상관 계수 계산 (공분산 또는 표준 편차 없음).
이 방법을 사용하면 가장 직접적인 공식은 다음과 같습니다.
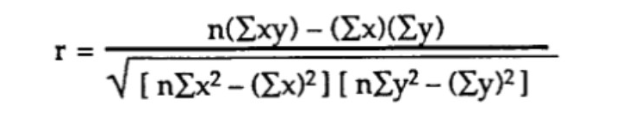
예를 들어 포도당 수준 (y)과 연령 (x)의 두 변수에 대한 n = 6 관측치가있는 데이터가 있다고 가정하면 계산은 다음 단계를 따릅니다.
1 단계) 기존 데이터 i, x, y로 테이블을 만들고 xy, x² 및 y²에 대한 빈 열을 추가합니다.
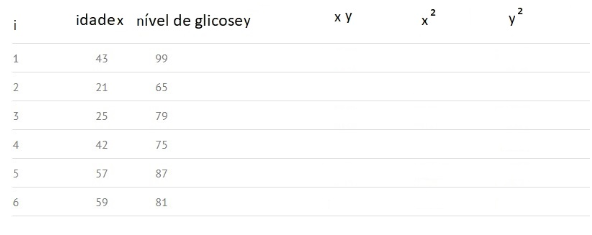
2 단계: x와 y를 곱하여 "xy"열을 채 웁니다. 예를 들어 1 행에는 x1y1 = 43 × 99 = 4257이 있습니다.

3 단계: x 열의 값을 제곱하고 x² 열에 결과를 기록합니다. 예를 들어, 첫 번째 줄에는 x가 있습니다.12 = 43 × 43 = 1849.

4 단계: 3 단계와 동일하게 y 열을 사용하고 y² 열에 값의 제곱을 기록합니다. 예를 들어 첫 번째 줄에는 y가 있습니다.12 = 99 × 99 = 9801.

5 단계: 모든 열 번호의 합계를 구하고 결과를 열 바닥 글에 배치합니다. 예를 들어 Age X 열의 합은 43 + 21 + 25 + 42 + 57 + 59 = 247입니다.

6 단계: 위의 공식을 사용하여 상관 계수를 얻습니다.

그래서 우리는 :

Spearman의 상관 계수 계산
Spearman의 상관 계수 계산은 약간 다릅니다. 이를 위해 데이터를 다음 표에 정리해야합니다.
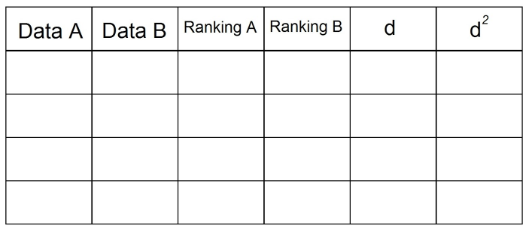
1. 두 쌍의 데이터가있는 문에 테이블에 포함시켜야합니다. 예를 들면 :
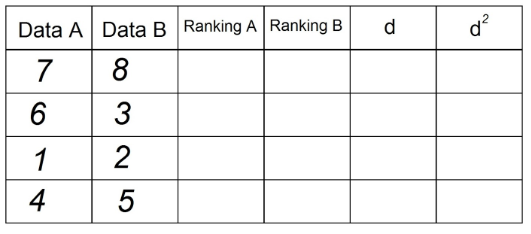
2. "순위 A"열에서 "날짜 A"에있는 관찰을 오름차순으로 정렬합니다. "1"은 열에서 가장 낮은 값이고 n (총 관측 수)은 "날짜"열에서 가장 높은 값입니다. 그만큼". 이 예에서는 다음과 같습니다.
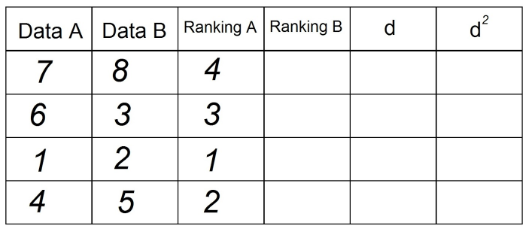
3. 이제 "데이터 B"열의 관찰을 사용하여 "순위 B"열을 얻기 위해 동일한 작업을 수행합니다.
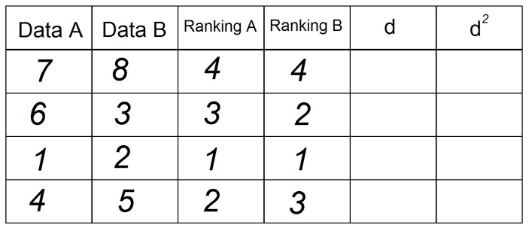
4. "d"열에는 두 순위 (A-B)의 차이가 표시됩니다. 여기서 신호는 중요하지 않습니다.

5. "d"열의 각 값을 제곱하고 d² 열에 기록합니다.
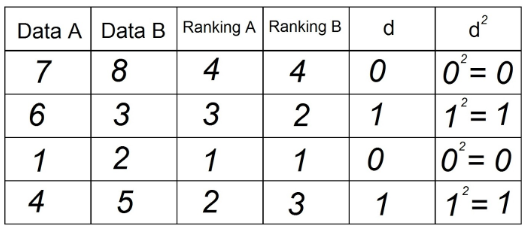
6. "d²"열의 모든 데이터를 합산합니다. 이 값은 Σd²입니다. 이 예에서 Σd² = 0 + 1 + 0 + 1 = 2
7. 이제 Spearman의 공식을 사용합니다.
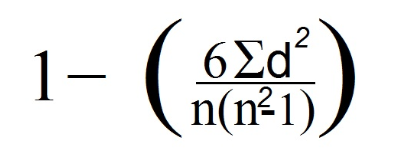
우리의 경우, 데이터 라인 수 (관측치 수에 해당)를 볼 때 n은 4와 같습니다.
8. 마지막으로 이전 공식의 데이터를 대체했습니다.
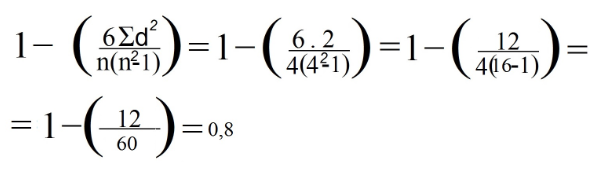
선형 회귀
선형 회귀는 다른 변수 (x)의 값을 알고있을 때 변수 (y)의 가능한 값을 추정하는 데 사용되는 공식입니다. "x"값은 독립 또는 설명 변수이고 "y"는 종속 변수 또는 응답입니다.
선형 회귀는 "y"값이 변수 "x"의 함수로 어떻게 변할 수 있는지 확인하는 데 사용됩니다. 분산 검사 값을 포함하는 선을 선형 회귀선이라고합니다.
설명 변수 "x"에 단일 값이 있으면 회귀가 호출됩니다. 단순 선형 회귀.
