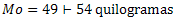統計内では、それぞれの場合の必要性に応じて、データセットを分析するいくつかの方法があります。 コーチが各ランニングワークアウトで各アスリートが費やした時間を書き留めてから、 一部のランナーのタイミングにはかなりのばらつきがあり、競技で敗北する可能性があります。 公式。 この場合、コーチが各アスリートの時間のばらつきをチェックする方法を持っているのは興味深いことです。
もちろん、Statisticsにはこのトレーナーに適したツールがあります。 THE 分散 です 分散測定これにより、各アスリートの時間の平均値からの距離を特定できます。 コーチが5つの異なる日に同じコースを完了した後、3人のアスリートの時間を表に記録したとします。

分散を計算する前に、 算術平均(バツ) 各アスリートの時代。 そのために、コーチは次の計算を行いました。
João → バツJ = 63 + 60 + 59 + 55 + 62 = 299 = 59.8分.
5 5
ピーター → バツP = 54 + 59 + 60 + 57 + 61 = 291 = 58.2分
5 5
フレーム → バツM = 60 + 63 + 58 + 62 + 55 = 298 = 59.6分.
5 5
コーチは各アスリートの平均時間を知ったので、分散を使用して、この平均値から各レースの期間の距離を取得できます。 各コリドーの分散を計算するには、次の計算を実行できます。
Var = (1日目 - バツ)²+(2日目- バツ)²+(3日目- バツ)²+(4日目- バツ)²+(5日目- バツ)²
合計日数(5)
各アスリートについて、コーチは分散を計算しました。
João
変数(J)= (63 – 59,8)² + (60 – 59,8)² + (59 – 59,8)² + (55 – 59,8)² + (62 – 59,8)²
5
今やめないで... 広告の後にもっとあります;)
変数(J)= 10,24 + 0,04 + 0,64 + 23,04 + 4,84
5
変数(J)= 38,8
5
変数(J)= 7.76分
ピーター
変数(P)= (54 – 58,2)² + (59 – 58,2)² + (60 – 58,2)² + (57 – 58,2)² + (61 – 58,2)²
5
変数(P)= 17,64 + 0,64 + 3,24 + 1,44 + 7,84
5
変数(P)= 30,8
5
変数(P)= 6.16分
フレーム
変数(M)= (60 – 59,6)² + (63 – 59,6)² + (58 – 59,6)² + (62 – 59,6)² + (55 – 59,6)²
5
変数(M)= 0,16 + 11,56 + 2,56 + 5,76 + 21,16
5
変数(M)= 41,2
5
変数(M)= 8.24分
分散計算によると、時間を提示するアスリート より分散 平均のは フレーム。 既に ピーター 他のランナーよりも平均に近い時間を提示しました。
この例で分散について見たすべてを合成するのはどうですか?
データのセットが与えられた場合、分散は、そのセットの各値が中央(平均)値からどれだけ離れているかを示す分散の尺度です。
分散が小さいほど、値は平均に近くなります。 同様に、それが大きいほど、値は平均から遠くなります。
この例のように、次の分散を計算します。 すべて コーチの監督の下でアスリートがトレーニングした日、私たちは計算したと言います 母分散. ここで、コーチが1年間のこれらのアスリートの時間を分析したいとします。 大量のデータになりますね。 この場合、研究者は、サンプルの一種である少数の時間記録のみを選択することが適切です。 この計算は次のようになります サンプル分散. サンプルの分散と実行した計算の唯一の違いは、除数が1から差し引かれた日数であるということです。
変数 サンプル= (日から- バツ)²+(b日目- バツ)²+(c日目– バツ)² +... +(n日目– バツ)²
(合計日数)-1
アマンダ・ゴンサルベス
数学を卒業