
相関は類似性を意味しますまたは 人とアイデアの2つの関係. これは、2つの異なる仮説、状況、またはオブジェクトの間に存在する類似性または同等性です。
統計学と数学の分野では、相関とは、関連する2つ以上の変数間の尺度を指します。
相関という用語はラテン語に由来する女性名詞です 相関します。
相関という言葉は、関係、同等性、ネクサス、対応、類推、接続などの同義語に置き換えることができます。
相関係数
統計では ピアソンの相関係数 (r)は、積-運動量相関係数とも呼ばれ、同じメトリックスケール内の2つの変数間に存在する関係を測定します。
相関係数の機能は、既知のデータまたは情報のセット間に存在する関係の強さを決定することです。
相関係数の値は-1から1の間で変化する可能性があり、得られた結果によって、相関が負か正かが決まります。
係数を解釈するには、1は変数間の相関が パーフェクトポジティブ -1はそれが 完全なネガティブ. 係数が0に等しい場合は、変数が相互に依存していないことを意味します。
統計には、 スピアマンの相関係数、統計学者チャールズスピアマンにちなんで名付けられました。 この係数の機能は、線形であるかどうかに関係なく、2つの変数間の関係の強度を測定することです。
スピアマンの相関は、分析された2つの変数間の関係の強度を評価するのに役立ちます 単調関数(順序関係を保持または反転する数学関数)で測定できます。 初期)。
ピアソンの相関係数の計算
方法1)共分散と標準偏差を使用したピアソンの相関係数の計算。
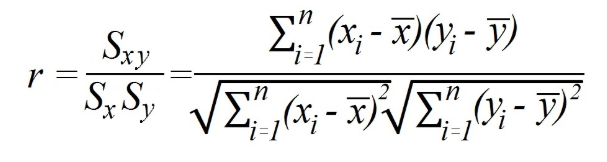
どこ
sXY共分散です。
sバツ そして syx変数とy変数の標準偏差をそれぞれ表します。
この場合、計算には、最初に変数間の共分散と、各変数の標準偏差を見つけることが含まれます。 次に、標準偏差を乗算して共分散を除算します。
多くの場合、ステートメントは、式を適用するだけで、変数の標準偏差または変数間の共分散のいずれかをすでに提供しています。
方法2)ピアソンの生データとの相関係数の計算(共分散または標準偏差なし)。
この方法では、最も直接的な式は次のとおりです。
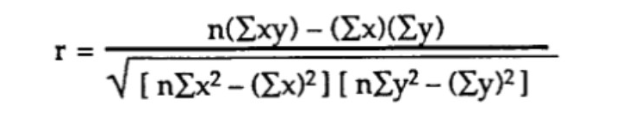
たとえば、血糖値(y)と年齢(x)の2つの変数のn = 6の観測値を持つデータがあるとすると、計算は次の手順に従います。
手順1)既存のデータi、x、yを使用してテーブルを作成し、xy、x²、y²の空白の列を追加します。
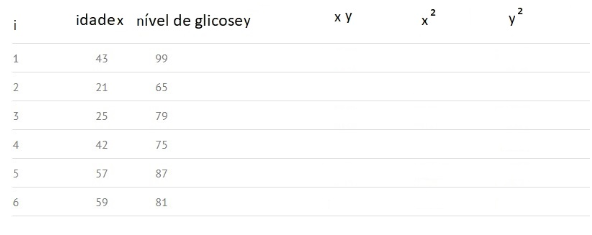
ステップ2:xとyを掛けて、「xy」列を埋めます。 たとえば、1行目では、x1y1 = 43×99 = 4257になります。

ステップ3:列xの値を二乗し、結果を列x²に記録します。 たとえば、最初の行にはxがあります12 = 43 × 43 = 1849.

ステップ4:ステップ3と同じように、列yを使用して、値の2乗を列y²に記録します。 たとえば、最初の行には次のようになります。y12 = 99 × 99 = 9801.

ステップ5:すべての列番号の合計を取得し、その結果を列フッターに配置します。 たとえば、列AgeXの合計は43+ 21 + 25 + 42 + 57 + 59 = 247に等しくなります。

ステップ6:上記の式を使用して、相関係数を取得します。

だから私たちは持っています:

スピアマンの相関係数の計算
スピアマンの相関係数の計算は少し異なります。 そのためには、次の表にデータを整理する必要があります。
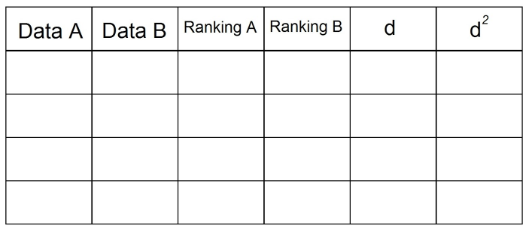
1. ステートメントに2組のデータがあるので、それらを表に導入する必要があります。 例えば:
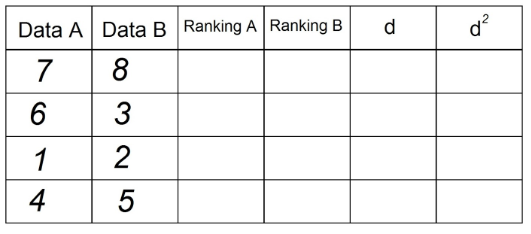
2. 「ランキングA」列では、「日付A」にある観測値を昇順で並べ替えます。 「1」は列の最小値であり、n(観測の総数)は「日付」列の最大値です。 THE」。 この例では、次のようになります。
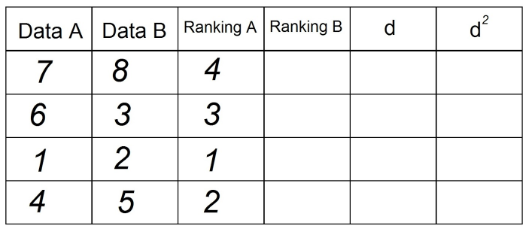
3. 「データB」列の観測値を使用して、「ランキングB」列を取得するために同じことを行います。
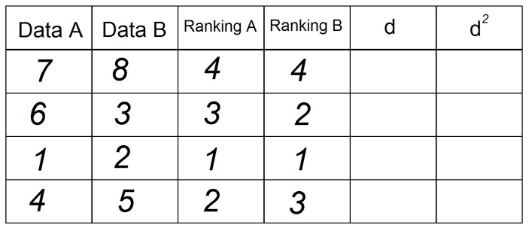
4. 列「d」には、2つのランキングの差(A〜B)を示します。 ここでは信号は重要ではありません。

5. 列「d」の各値を二乗し、列d²に記録します:
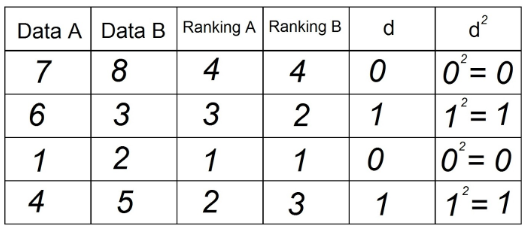
6. 列「d²」のすべてのデータを合計します。 この値はΣd²です。 この例では、Σd²= 0 + 1 + 0 + 1 = 2
7. ここで、スピアマンの式を使用します。
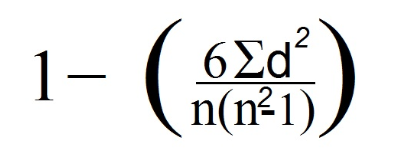
この場合、データ行の数(観測値の数に対応)を見ると、nは4に等しくなります。
8. 最後に、前の式のデータを置き換えました。
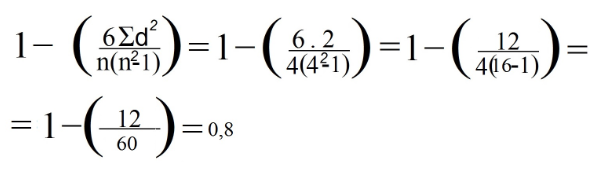
線形回帰
線形回帰は、他の変数(x)の値がわかっている場合に、変数(y)の可能な値を推定するために使用される式です。 「x」の値は独立変数または説明変数であり、「y」は従属変数または応答です。
線形回帰は、「y」の値が変数「x」の関数としてどのように変化するかを確認するために使用されます。 分散チェック値を含む線は、線形回帰線と呼ばれます。
説明変数「x」が単一の値を持っている場合、回帰は呼び出されます 単純な線形回帰.

