
सहसंबंध का अर्थ है समानता या दो चीजों, लोगों या विचारों के बीच संबंध. यह एक समानता या तुल्यता है जो दो अलग-अलग परिकल्पनाओं, स्थितियों या वस्तुओं के बीच मौजूद होती है।
सांख्यिकी और गणित के क्षेत्र में, सहसंबंध दो या दो से अधिक चर के बीच एक माप को संदर्भित करता है जो संबंधित हैं।
सहसंबंध शब्द एक स्त्री संज्ञा है जो लैटिन से आया है comes सहसंबद्ध।
सहसंबंध शब्द को पर्यायवाची शब्दों से बदला जा सकता है जैसे: संबंध, तुल्यता, सांठगांठ, पत्राचार, सादृश्य और संबंध।
सहसंबंध गुणांक
आंकड़ों में पियर्सन का सहसंबंध गुणांक (आर), जिसे उत्पाद-गति सहसंबंध गुणांक भी कहा जाता है, एक ही मीट्रिक पैमाने के भीतर दो चर के बीच मौजूद संबंध को मापता है।
सहसंबंध गुणांक का कार्य ज्ञात डेटा या जानकारी के सेट के बीच मौजूद संबंध की ताकत का निर्धारण करना है।
सहसंबंध गुणांक का मान -1 और 1 के बीच भिन्न हो सकता है और प्राप्त परिणाम परिभाषित करता है कि सहसंबंध नकारात्मक है या सकारात्मक।
गुणांक की व्याख्या करने के लिए, यह जानना आवश्यक है कि 1 का अर्थ है कि चरों के बीच संबंध है पूर्ण सकारात्मक और -1 का मतलब यह है पूर्ण नकारात्मक. यदि गुणांक 0 के बराबर है तो इसका मतलब है कि चर एक दूसरे पर निर्भर नहीं हैं।
आंकड़ों में भी है also स्पीयरमैन सहसंबंध गुणांक, सांख्यिकीविद् चार्ल्स स्पीयरमैन के नाम पर। इस गुणांक का कार्य दो चरों के बीच संबंध की तीव्रता को मापना है, चाहे वे रैखिक हों या नहीं।
स्पीयरमैन सहसंबंध यह आकलन करने का कार्य करता है कि क्या दो विश्लेषण किए गए चर के बीच संबंध की तीव्रता है एक नीरस कार्य द्वारा मापा जा सकता है (गणितीय कार्य जो क्रम संबंध को संरक्षित या उलट देता है or प्रारंभिक)।
पियर्सन के सहसंबंध गुणांक की गणना
विधि 1) सहप्रसरण और मानक विचलन का उपयोग करते हुए पियर्सन के सहसंबंध गुणांक की गणना।
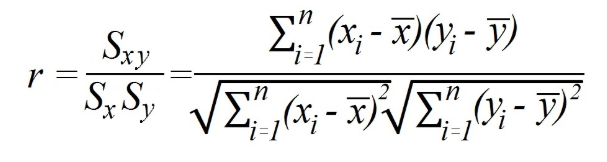
कहा पे
रोंXYसहप्रसरण है;
रोंएक्स तथा रोंआपक्रमशः x और y चरों के मानक विचलन को निरूपित करते हैं।
इस मामले में, गणना में पहले चर के बीच सहप्रसरण और उनमें से प्रत्येक के मानक विचलन का पता लगाना शामिल है। फिर मानक विचलन को गुणा करके सहप्रसरण को विभाजित करें।
अक्सर, कथन पहले से ही या तो चरों के मानक विचलन प्रदान करता है, या उनके बीच सहप्रसरण, केवल सूत्र को लागू करके।
विधि 2) कच्चे डेटा के साथ पियर्सन के सहसंबंध गुणांक की गणना (कोई सहप्रसरण या मानक विचलन नहीं)।
इस पद्धति के साथ, सबसे प्रत्यक्ष सूत्र इस प्रकार है:
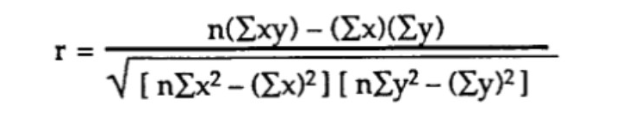
उदाहरण के लिए, मान लें कि हमारे पास दो चरों के n=6 अवलोकन के साथ डेटा है: ग्लूकोज स्तर (y) और आयु (x), गणना इन चरणों का पालन करती है:
चरण 1) मौजूदा डेटा के साथ तालिका बनाएं: i, x, y, और xy, x² और y² के लिए रिक्त कॉलम जोड़ें:
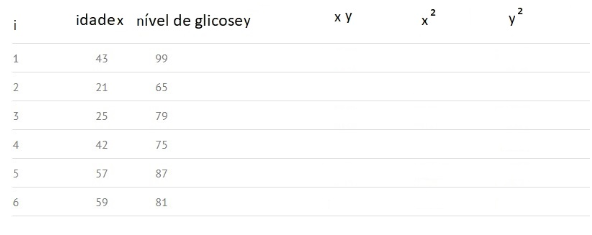
चरण 2: "xy" कॉलम भरने के लिए x और y को गुणा करें। उदाहरण के लिए, पंक्ति 1 में हमारे पास होगा: x1y1 = 43 × 99 = 4257।

चरण 3: कॉलम x में मानों को स्क्वायर करें, और परिणाम कॉलम x² में रिकॉर्ड करें। उदाहरण के लिए, पहली पंक्ति में हमारे पास x. होगा12 = 43 × 43 = 1849.

चरण ४: चरण ३ की तरह ही करें, अब कॉलम y का उपयोग करें और कॉलम y² में अपने मूल्यों के वर्ग को रिकॉर्ड करें। उदाहरण के लिए, पहली पंक्ति में हमारे पास होगा: y12 = 99 × 99 = 9801.

चरण 5: सभी कॉलम नंबरों का योग प्राप्त करें और परिणाम को कॉलम फुटर में रखें। उदाहरण के लिए, स्तंभ आयु X का योग 43+21+25+42+57+59 = 247 के बराबर है।

चरण 6: सहसंबंध गुणांक प्राप्त करने के लिए उपरोक्त सूत्र का उपयोग करें:

तो हमारे पास:

स्पीयरमैन के सहसंबंध गुणांक की गणना
स्पीयरमैन के सहसंबंध गुणांक की गणना थोड़ी अलग है। उसके लिए, हमें अपने डेटा को निम्न तालिका में व्यवस्थित करने की आवश्यकता है:
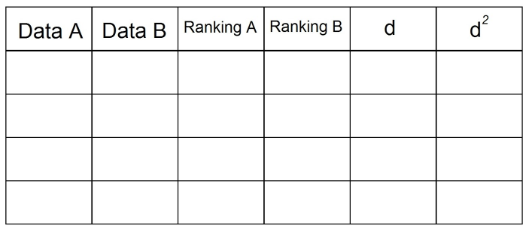
1. कथन में डेटा के 2 जोड़े होने के कारण, हमें उन्हें तालिका में प्रस्तुत करना होगा। उदाहरण के लिए:
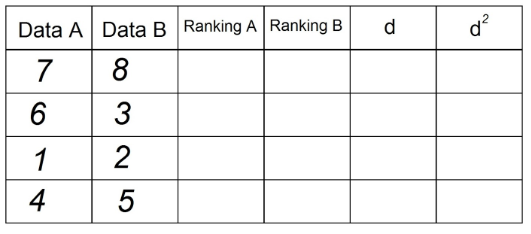
2. "रैंकिंग ए" कॉलम में, हम उन अवलोकनों को क्रमबद्ध करेंगे जो "दिनांक ए" में आरोही रूप से हैं, "1" कॉलम में सबसे कम मूल्य, और एन (अवलोकन की कुल संख्या) "दिनांक" कॉलम में उच्चतम मूल्य द"। हमारे उदाहरण में यह है:
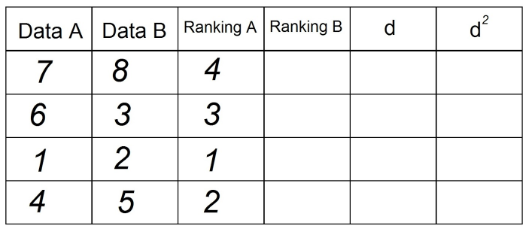
3. हम "डेटा बी" कॉलम में अब टिप्पणियों का उपयोग करके "रैंकिंग बी" कॉलम प्राप्त करने के लिए ऐसा ही करते हैं:
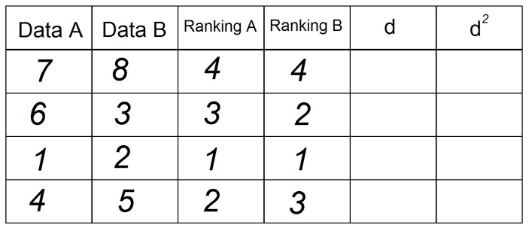
4. कॉलम "डी" में हम दो रैंकिंग (ए - बी) के बीच अंतर डालते हैं। यहां सिग्नल मायने नहीं रखता।

5. कॉलम "डी" में प्रत्येक मान को स्क्वायर करें और कॉलम डी² में रिकॉर्ड करें:
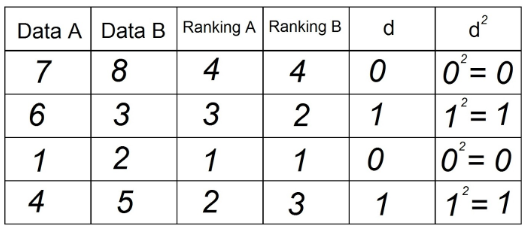
6. कॉलम "डी²" से सभी डेटा का योग करें। यह मान d² है। हमारे उदाहरण में d² = 0+1+0+1 = 2
7. अब हम स्पीयरमैन के सूत्र का उपयोग करते हैं:
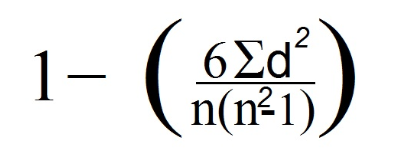
हमारे मामले में, n 4 के बराबर है, जैसा कि हम डेटा लाइनों की संख्या को देखते हैं (जो टिप्पणियों की संख्या से मेल खाती है)।
8. अंत में, हमने डेटा को पिछले सूत्र में बदल दिया:
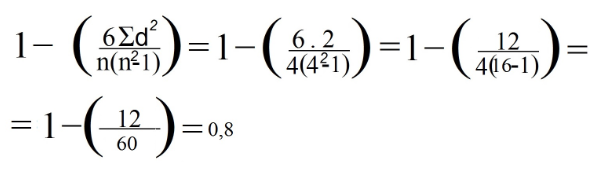
रेखीय प्रतिगमन
रैखिक प्रतिगमन एक सूत्र है जिसका उपयोग एक चर (y) के संभावित मूल्य का अनुमान लगाने के लिए किया जाता है जब अन्य चर (x) के मान ज्ञात होते हैं। "x" का मान स्वतंत्र या व्याख्यात्मक चर है और "y" आश्रित चर या प्रतिक्रिया है।
रैखिक प्रतिगमन का उपयोग यह देखने के लिए किया जाता है कि "y" का मान चर "x" के कार्य के रूप में कैसे भिन्न हो सकता है। वेरिएंस चेक वैल्यू वाली लाइन को लीनियर रिग्रेशन लाइन कहा जाता है।
यदि व्याख्यात्मक चर "x" का एक ही मान है, तो प्रतिगमन कहा जाएगा सरल रैखिक प्रतिगमन.
